고객의 정기예금 가입 여부 예측을 위한 은행 마케팅 분류 모델 구축
- 자전거 대여 수요 예측을 위한 머신러닝 모델 구축
- 파이썬 데이터분석 - A/B test 분석
- 파이썬 데이터분석 - aarrr 분석 실습
- 파이썬 데이터분석 - 장바구니 분석(연관분석)2 - FP-Growth, 순차패턴마이닝
- 파이썬 데이터분석 - 장바구니 분석(연관분석) 실습
- 파이썬 데이터분석 - 장바구니 분석(연관분석)
- 파이썬 데이터분석 데이터시각화 실습
- 파이썬 데이터분석 데이터시각화2
- 파이썬 데이터분석 데이터시각화1
- 파이썬 데이터분석 클러스터와 차원축소 실습
- 파이썬 데이터분석 클러스터와 차원축소2
- 파이썬 데이터분석 클러스터와 차원축소
- 파이썬 데이터분석 라이브러리
1. 분석 목적 및 목표
- 분석 목적 : 포르투갈 A은행의 마케팅 담당자로서 고객이 정기 예금을 가입할 가능성을 예측하고자 정기 예금과 관련이 있는 요소들을 파악하여 마케팅 캠페인의 효율성 제고하고자 한다
- 분석 목표 : 결정 트리와 앙상블 기법을 사용하여 고객이 정기 예금을 가입할지 여부를 예측하는 분류 모델을 구축하여 인사이트를 바탕으로 비즈니스 전략을 제시하고자 한다
2. 데이터 소개
- 본 분석은 UC Irvine Machine Learning Repository에서 제공하는 Bank Marketing 데이터를 활용하였다
- 2008년 부터 2010년까지의 포르투갈 은행의 마케팅 캠페인 결과를 설명하는 데이터셋을 분석하였다
- 데이터는 전화 통화 기반 마케팅 캠페인으로서 고객이 정기 예금을 가입하기로 동의했다면 목표변수(target)y에
yes라고 표시되었다
| 컬럼명 | 설명 |
|---|---|
| age | 나이 (숫자) |
| job | 직업 (범주형) |
| marital | 결혼 여부 (범주형) |
| education | 교육 수준 (범주형) |
| default | 신용 불량 여부 (범주형) |
| housing | 주택 대출 여부 (범주형) |
| loan | 개인 대출 여부 (범주형) |
| contact | 연락 유형 (범주형) |
| month | 마지막 연락 월 (범주형) |
| day_of_week | 마지막 연락 요일 (범주형) |
| duration | 마지막 연락 지속 시간, 초 단위 (숫자) |
| campaign | 캠페인 동안 연락 횟수 (숫자) |
| pdays | 이전 캠페인 후 지난 일수 (숫자) |
| previous | 이전 캠페인 동안 연락 횟수 (숫자) |
| poutcome | 이전 캠페인의 결과 (범주형) |
| emp.var.rate | 고용 변동률 (숫자) |
| cons.price.idx | 소비자 물가지수 (숫자) |
| cons.conf.idx | 소비자 신뢰지수 (숫자) |
| euribor3m | 3개월 유리보 금리 (숫자) |
| nr.employed | 고용자 수 (숫자) |
| y | 정기 예금 가입 여부 (이진: yes=1, no=0) |
- Input variables:
- bank client data:
- age (numeric)
- job : type of job (categorical: “admin.”,”blue-collar”,”entrepreneur”,”housemaid”,”management”,”retired”,”self-employed”,”services”,”student”,”technician”,”unemployed”,”unknown”)
- marital : marital status (categorical: “divorced”,”married”,”single”,”unknown”; note: “divorced” means divorced or widowed)
- education (categorical: “basic.4y”,”basic.6y”,”basic.9y”,”high.school”,”illiterate”,”professional.course”,”university.degree”,”unknown”)
- default: has credit in default? (categorical: “no”,”yes”,”unknown”)
- housing: has housing loan? (categorical: “no”,”yes”,”unknown”)
- loan: has personal loan? (categorical: “no”,”yes”,”unknown”)
- related with the last contact of the current campaign:
- contact: contact communication type (categorical: “cellular”,”telephone”)
- month: last contact month of year (categorical: “jan”, “feb”, “mar”, …, “nov”, “dec”)
- day_of_week: last contact day of the week (categorical: “mon”,”tue”,”wed”,”thu”,”fri”)
- duration: last contact duration, in seconds (numeric). Important note: this attribute highly affects the output target (e.g., if duration=0 then y=”no”). Yet, the duration is not known before a call is performed. Also, after the end of the call y is obviously known. Thus, this input should only be included for benchmark purposes and should be discarded if the intention is to have a realistic predictive model.
- other attributes:
- campaign: number of contacts performed during this campaign and for this client (numeric, includes last contact)
- pdays: number of days that passed by after the client was last contacted from a previous campaign (numeric; 999 means client was not previously contacted)
- previous: number of contacts performed before this campaign and for this client (numeric)
- poutcome: outcome of the previous marketing campaign (categorical: “failure”,”nonexistent”,”success”)
- social and economic context attributes
- emp.var.rate: employment variation rate - quarterly indicator (numeric)
- cons.price.idx: consumer price index - monthly indicator (numeric)
- cons.conf.idx: consumer confidence index - monthly indicator (numeric)
- euribor3m: euribor 3 month rate - daily indicator (numeric)
- nr.employed: number of employees - quarterly indicator (numeric)
- Output variable (desired target):
- y - has the client subscribed a term deposit? (binary: “yes”,”no”)
3. EDA
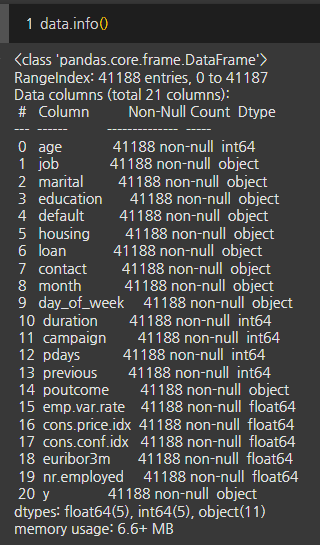
- 본 데이터셋은 41,188행과 21열로 구성되어 결측치는 관찰되지 않았다
- 총 12건의 중복 데이터가 관찰되었고, 불필요한 값이라고 판단되어 중복값을 제거하였다
- pdays(이전 캠페인 후 지난 일수)는 숫자 단위이지만 고객에게 연락하지 않은 데이터인 ‘999’값이 존재하므로 범주형으로 변환하였다
1
2
3
data = data.drop_duplicates()
data = data.reset_index(drop=True)
data['pdays'] = data['pdays'].astype('object')
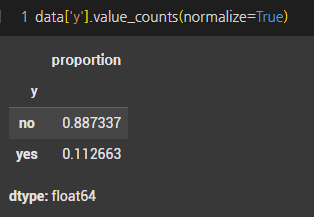
- 목표변수는 89%의 ‘아니오’와 11%의 ‘예’의 답으로 불균형한 형태를 가지고있다.
- 데이터 불균형을 SMOTE를 활용하여 실험을 진행하고자 한다
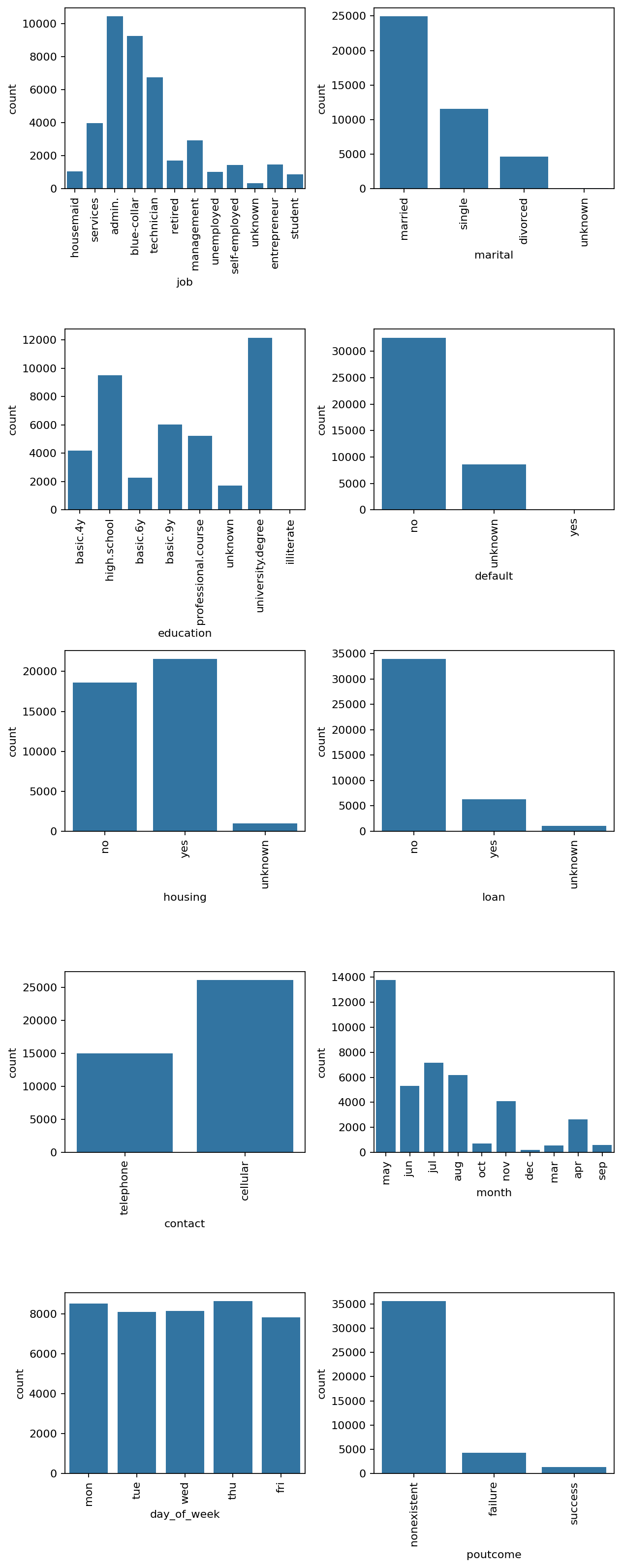
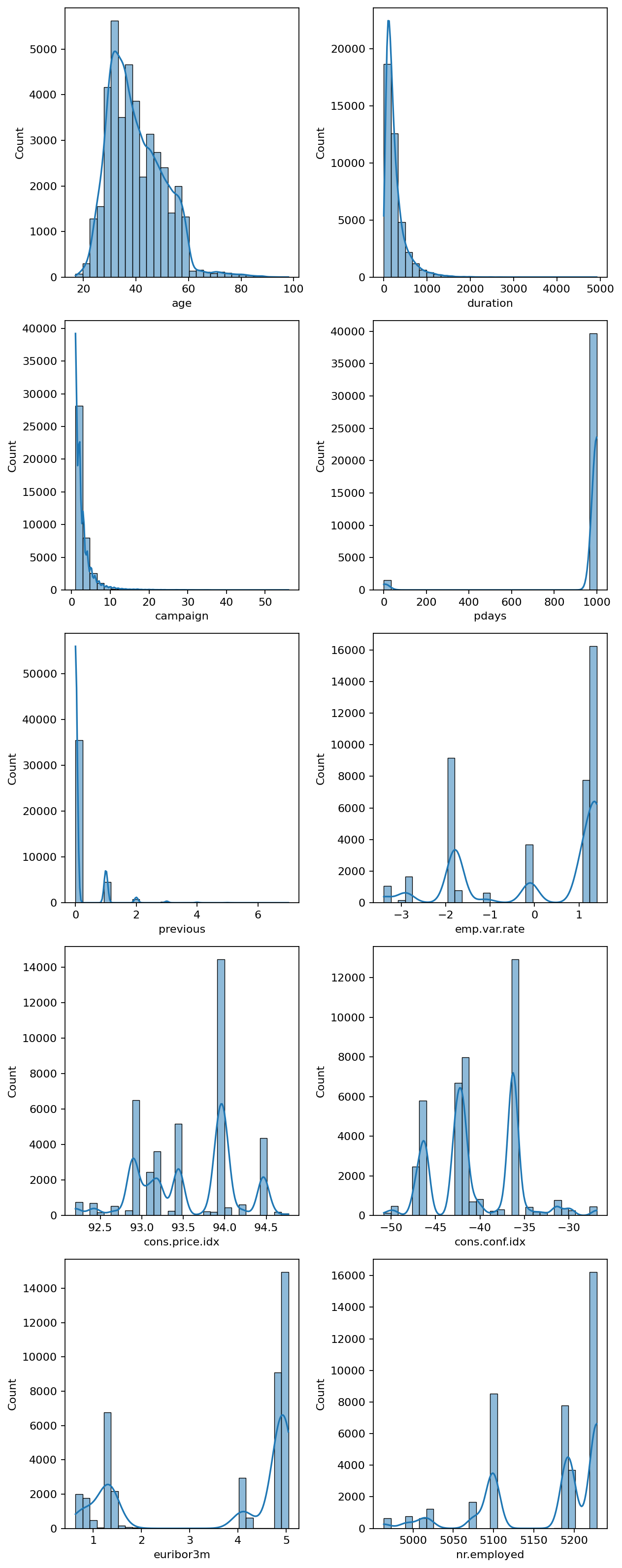
- 변수 중 분류되지 않은
unknown값이 존재한다 - 캠페인은 평일에만 시행된것으로 나타난다
- 고용 변동률(emp.var.rate)이 높게 관찰돼 경제상황으로 인해 일자리 변동이 있을때 캠페인을 시행한 것으로 판단된다
- 소비자 물가지수(cons.price.idx)는 높게 관찰됐으며, 이는 상품과 서비스에 대한 지불 능력이 좋은 상태를 보여준다
- 소비자 신뢰지수(cons.conf.idx)는 낮게 관찰되어 경제 변화에 대한 신뢰도가 낮은것으로 파악된다
- 3개월 유로리보 금리는 대출금리가 높아 대출에 어려움이 있을것으로 관찰된다
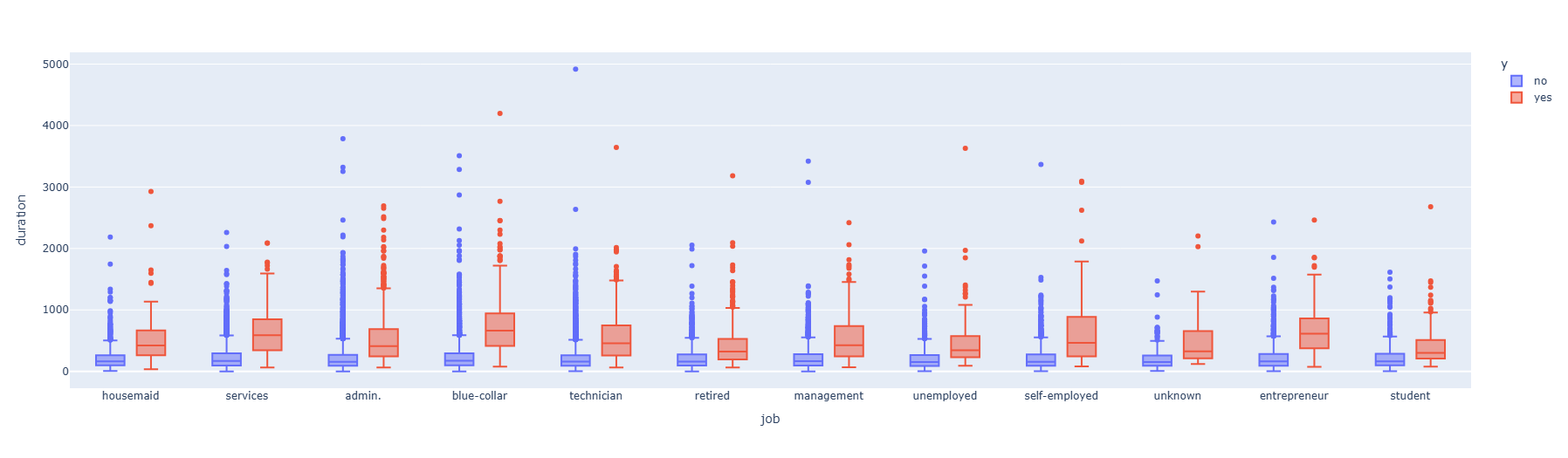
- 정기예금 미가입자는 통화시간이 짧은것으로 관찰됐다
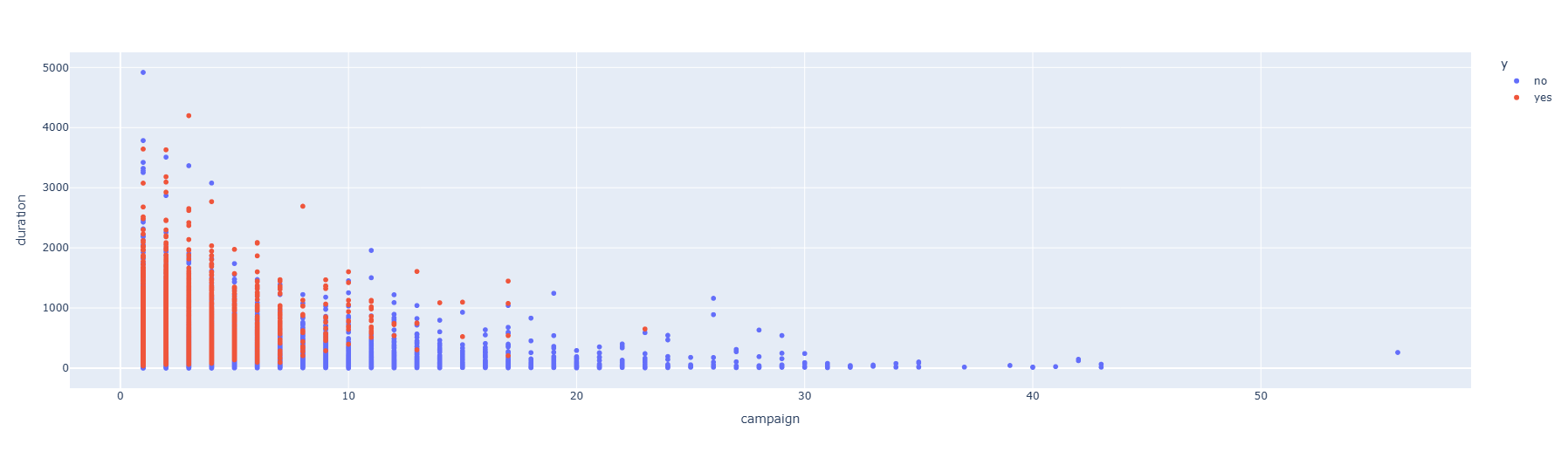
- 마케팅 캠페인 연락 횟수가 많아질수록 통화 시간은 감소하며 부정적인결과(미가입)로 도달되고있다
- 대부분의 정기예금 가입고객은 캠페인 초기에 결정되고있다
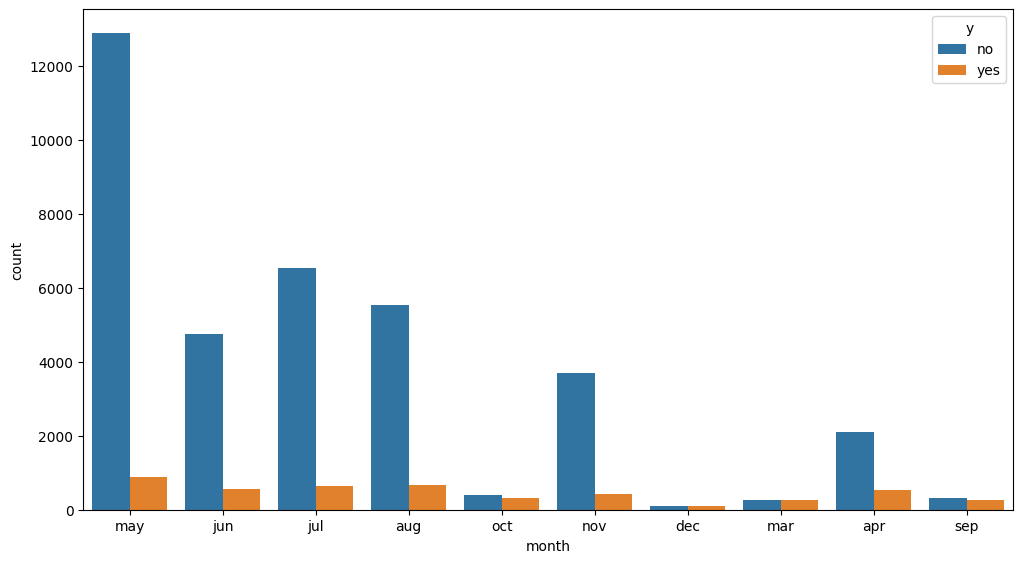
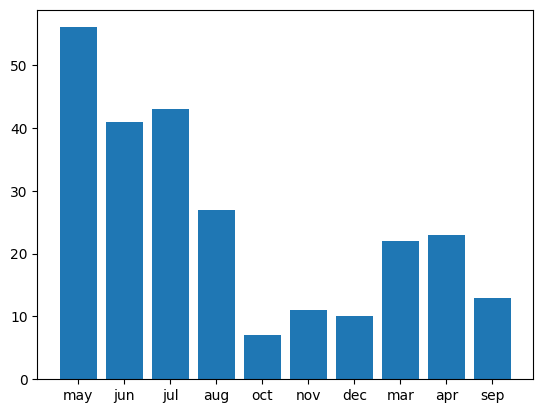
- 캠페인은 5월, 6월, 7월에 집중되어 있다
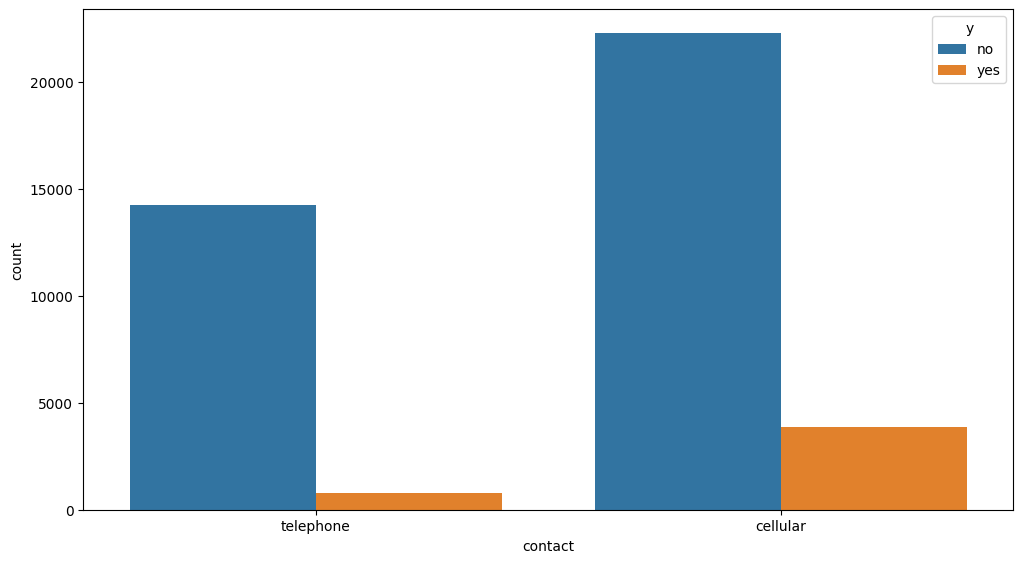
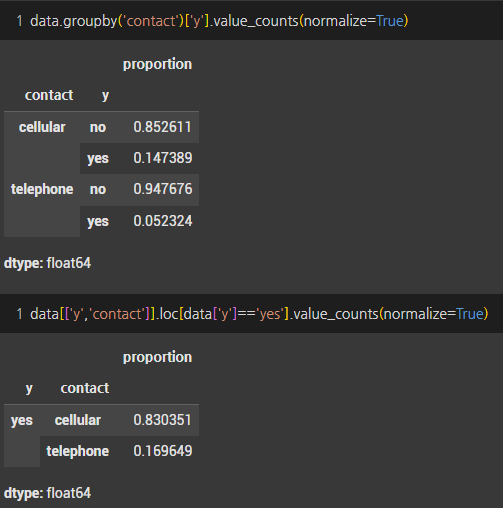
- 캠페인 연락유형은 cellular가 많았고, 정기예금 가입 고객도 약 15% 발생했다
- telephone을 통한 마케팅 캠페인은 가입 전환이 5%에 불과했다
- 정기예금 가입 고객중 cellular를 통해 가입한 고객이 83%를 차지했다
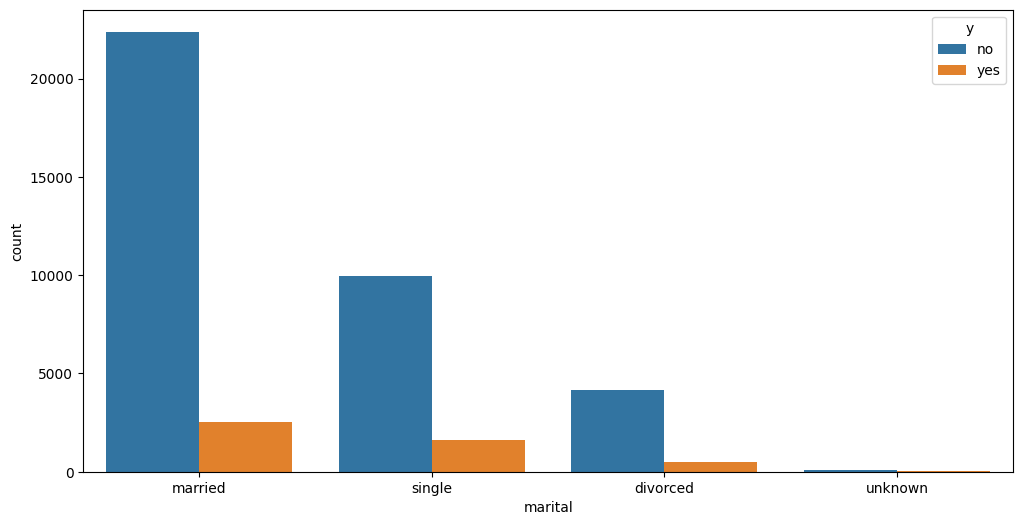
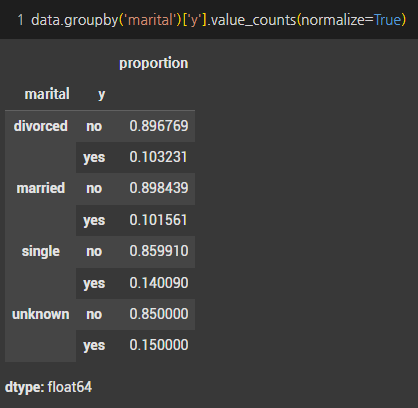
- 기혼자가 정기예금 가입을 가장 많이했지만, 비율 기준으로는 기혼자(10%)보다 미혼자(14%)의 전환율이 더 높은것으로 관찰됐다
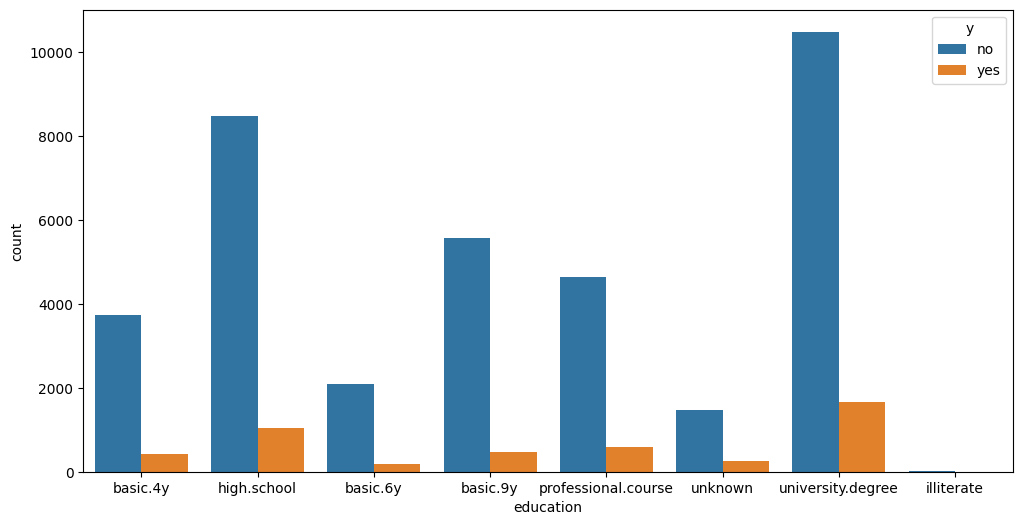
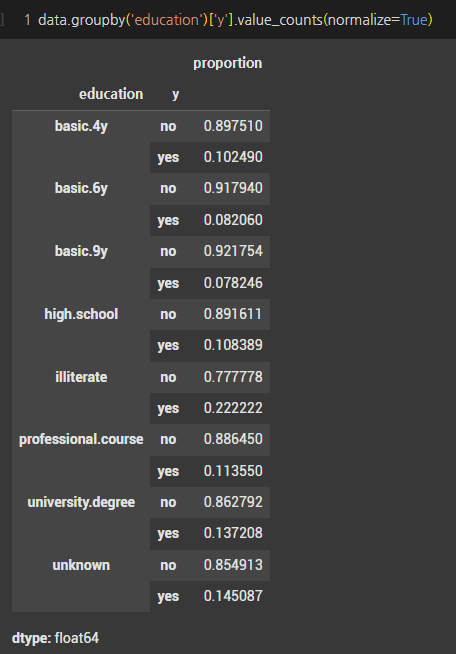
- 대졸고객이 정기예금을 가장 많이 가입하였고, 고졸고객이 뒤따랐다
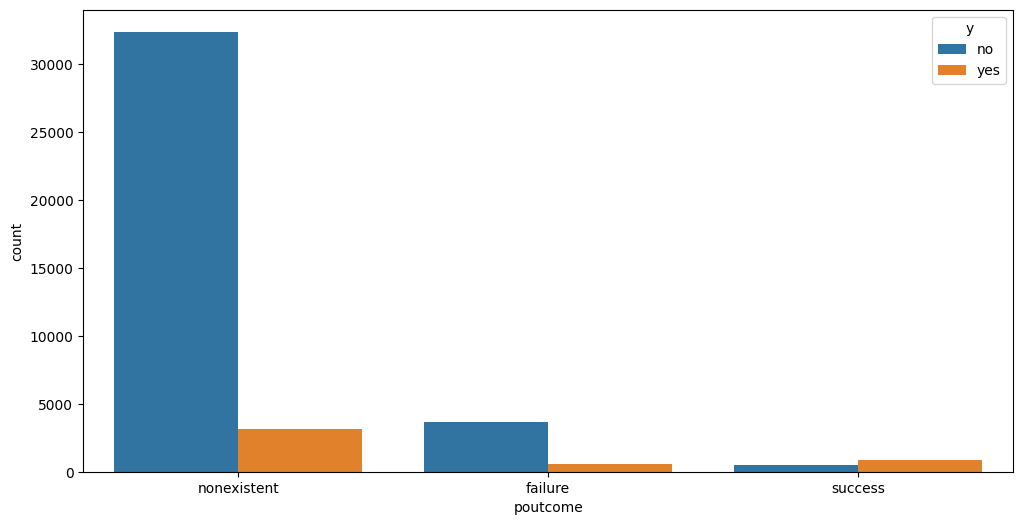
- 성공적인 마케팅 캠페인은 정기예금 가입 전환이 높은 반면, 실패한 캠페인의 전환율은 낮은것으로 관찰됐다. 이는 성공한 마케팅의 요인을 상세히 분석하여 고객별로 적절한 마케팅을 제안해야하는 의미를 나타내기도 한다
4. 베이스라인 모델 구축
- 자전거 대여 수량 예측을 위해 베이스라인 모델 구축 후 모델링 개선을 진행하고자 한다
- 베이스라인 모델은 앞서 진행한 EDA를 통해 모델 구축에 필요한 전처리 작업을 수행하고 진행하고자 한다
4-1. 데이터 전처리
- OrdinalEncoder를 사용하여 범주형 데이터를 정수로 변환하였다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 범주형 열 선택
cat_columns = list(data.select_dtypes(include=['object']).columns)[:-1]
cat_columns_w_target = list(data.select_dtypes(include=['object']).columns)
# 범주형 열을 문자열로 변환
data.loc[:, cat_columns] = data.loc[:, cat_columns].astype(str)
# Ordinal Encoder 적용
enc = OrdinalEncoder()
encoded_values = enc.fit_transform(data.loc[:, cat_columns_w_target])
encoded_df = pd.DataFrame(encoded_values, columns=cat_columns_w_target)
# 인코딩된 데이터프레임으로 원본 데이터프레임 업데이트
data[cat_columns_w_target] = encoded_df
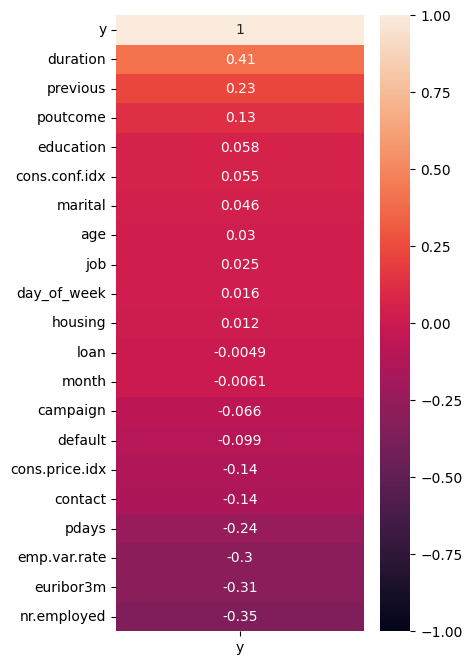
- 인코딩 작업후 상관관계를 확인해보니 목표변수와 주목해야할 변수는 다음과 같다
- duration(마지막 연락 지속 시간)
- previous(이전 캠페인 동안 연락 횟수)
- emp.var.rate(고용 변동률)
- euribor3m(3개월 유리보 금리)
- nr.employed(고용자 수)
4-2. 데이터 분류 (훈련vs테스트)
- 훈련 데이터와 테스트 데이터를 8:2로 분류하였다
1
2
3
4
5
6
7
X = data.columns[:-1]
y = data.columns[-1]
X_train, X_test, y_train, y_test = train_test_split(data[X], data[y],
stratify = data[y],
shuffle = True,
test_size = 0.2,
random_state=2023)
- 이번 분석에서는 아래와 같은 데이터 전처리 방법을 시도하여 베이스라인 모델의 성능을 비교하고, 교차 검증과 테스트 데이터에서의 결과를 바탕으로 하이퍼파라미터 튜닝을 위한 전처리 방법을 선택할 것이다
- 기본 데이터 : X_train, X_test, y_train, y_test
- 스케일링된 데이터 : X_train_scale, X_test_scale, y_train, y_test
- SMOTE를 사용한 데이터 : X_train_smote, X_test, y_train_smote, y_test
- 스케일링과 SMOTE를 결합한 데이터 : X_train_scale_smote, X_test_scale, y_train_smote, y_test
- SMOTE는 훈련 데이터에만 적용한다. 본 분석에서는 테스트 데이터에도 목표변수가 존재하지만, 실제로는 예측을 해야하기 때문에 테스트 데이터에는 적용하지 않는다.
1
2
3
4
5
6
7
8
9
10
scaler = StandardScaler()
X_train_scale = X_train.copy()
X_test_scale = X_test.copy()
X_train_scale[num_columns] = scaler.fit_transform(X_train_scale[num_columns])
X_test_scale[num_columns] = scaler.fit_transform(X_test_scale[num_columns])
smt = SMOTE(random_state=2023)
X_train_smote, y_train_smote = smt.fit_resample(X_train,y_train)
X_train_scale_smote, y_train_smote = smt.fit_resample(X_train_scale,y_train)
4-3. 교차 검증을 통한 베이스라인 모델 구축(CatBoost, LGBM, RandomForrest)
- 데이터의 불균형으로 인해 각 클래스의 비율을 유지하면서 모델을 평가하기 위해 StratifiedKFold를 사용하여 3개의 분할로 교차 검증을 수행하고자 한다
1
2
3
4
5
6
skf = StratifiedKFold(n_splits = 3, shuffle = True, random_state = 2023)
a = [X_train, X_train_scale, X_train_smote, X_train_scale_smote]
b = [y_train, y_train, y_train_smote, y_train_smote]
c = [X_test, X_test_scale, X_test, X_test_scale]
d = [y_test, y_test, y_test, y_test]
- 각 모델에 대해 F1 점수를 사용하여 교차 검증을 수행하는 함수 정의하였다
- 테스트 데이터에 대한 예측을 수행한 후, 정확도와 roc auc, 정밀도, 재현율, F1 점수 계산하고자 한다
1
2
3
4
5
6
7
8
9
10
def cv_f1(model,X,y, X_t, y_t):
f1_train = cross_val_score(model, X, y, scoring="f1", cv=skf)
model.fit(X,y)
pred = model.predict(X_t)
f1_test = f1_score(y_t, pred)
roc_test = roc_auc_score(y_test, pred)
acc_test = accuracy_score(y_test, pred)
pre_test = precision_score(y_test, pred)
rec_test = recall_score(y_test, pred, average='macro')
return f1_train.mean(), f1_test, roc_test, acc_test, pre_test, rec_test
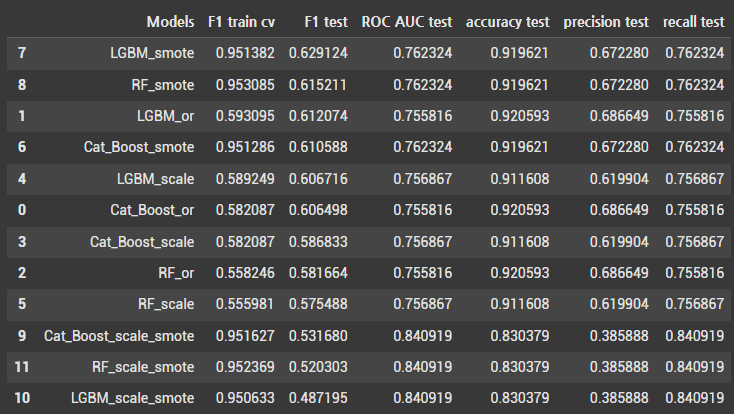
- 분석 결과
- 데이터 불균형 문제 : 데이터가 불균형하여 모델이 모든 예측을 ‘no’(0)로 할 경우에도 높은 정확도를 얻을 수 있다. 따라서 본 분석에서 정확도는 신뢰할 수 있는 성능 지표라 보기 어렵다
- 모델의 주요 목표는 ‘yes’(1)클래스를 올바르게 찾아내고 예측하는 것이다. 이러한 관점에서 재현율(recall)과 정밀도(precision)는 중요한 지표라고 볼 수 있다. 재현율은 실제 True인 것 중에서 모델이 올바르게 예측한 비율, 정밀도는 모델이 True라고 분류한 것 중에서 실제로 True인 것의 비율이다.
- F1 점수는 분류 모델에서 일반적으로 사용되는 지표로, 데이터가 불균형한 경우에도 모델의 재현율과 정밀도를 모두 평가하여 유용한 지표로 사용할 수 있다. F1 점수는 재현율과 정밀도의 조화 평균이므로, 두 지표 간의 균형을 고려하여 모델 성능을 평가할 수 있다
5. 하이퍼파라미터 튜닝
F1 점수를 기준으로 볼 때, 각 모델에서 SMOTE 전처리를 적용한 모델이 가장 높은 점수를 기록하였다. 따라서 SMOTE를 사용하여 개선된 모델 성능을 바탕으로 하이퍼파라미터 튜닝을 진행하고자 한다
StratifiedKFold와 Optuna SearchCV를 사용하고, trials 값은 50으로 설정하였다.

- 하이퍼파라미터 튜닝 결과 F1 점수 기준으로 랜덤포레스트 모델이 가장 좋은 성능을 보이고 있다
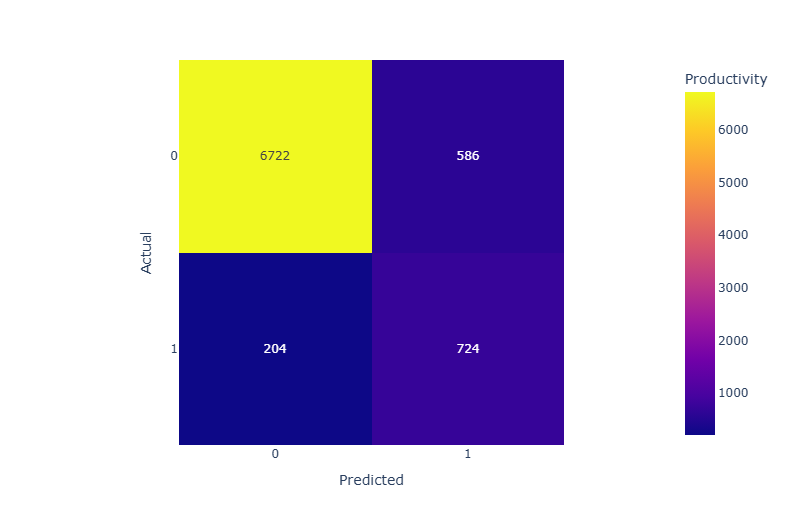
- F1 점수는 정밀도와 재현율의 조화 평균이므로, 추가적으로 confusion matrix를 살펴보고자 한다
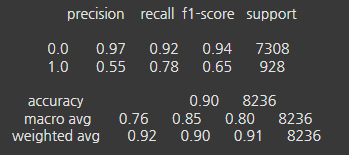
5-1. 랜덤포레스트
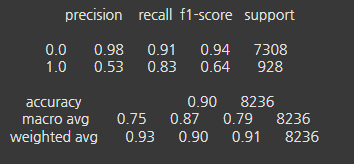
5-2. LGBM
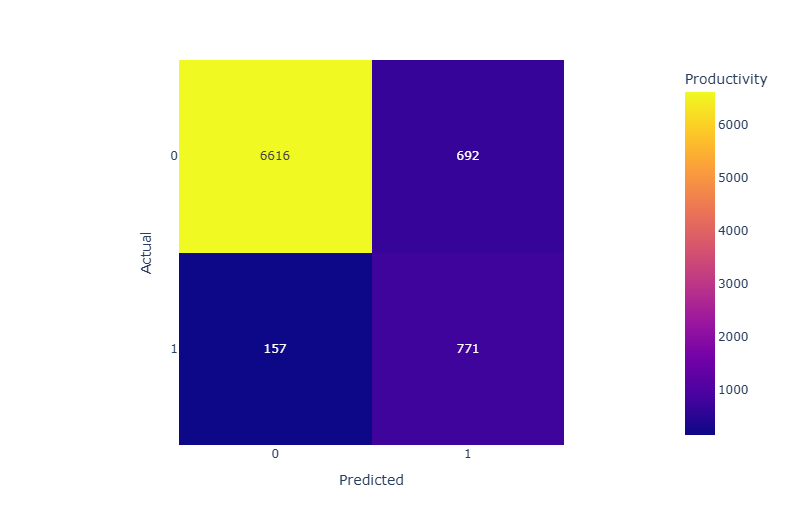
5-3. CatBoost
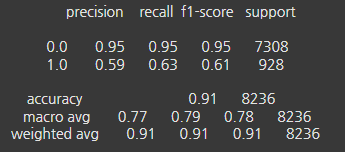
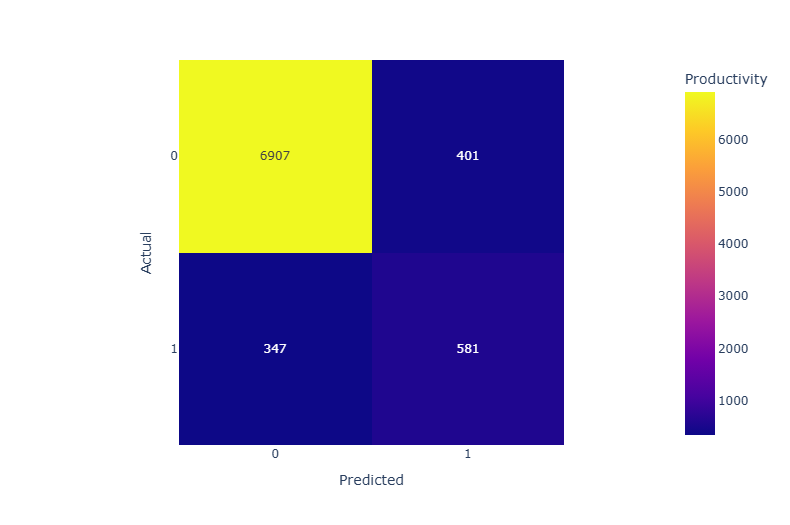
5-4. 분석결과
정밀도(Precision) : 랜덤포레스트와 LGBM의 0.0(음성) 클래스 정밀도가 매우 높고, 1.0(양성) 클래스의 정밀도는 모두 비슷하게 관찰됐다. LGBM이 0.0 클래스에서 가장 높은 정밀도를 보였다.
재현율(Recall) : 랜덤포레스트는 0.0 클래스에서 0.92, 1.0 클래스에서 0.78로 높은 재현율을 보였다. LGBM은 1.0 클래스에서 0.83으로 가장 높은 재현율을 보였다.
F1-score : 랜덤포레스트는 0.0 클래스에서 0.94로 가장 높은 F1 점수를 보였다. 1.0 클래스에서는 랜덤포레스트가 0.65로 가장 높지만, LGBM이 0.64로 근접하게 관찰됐다. CatBoost는 1.0 클래스에서 0.61로 다소 낮은 성능을 보였다.
정확도(Accuracy) : 세 모델 모두 비슷한 정확도를 보이지만, CatBoost가 0.91로 가장 높게 관찰됐다.
결론
- 각 모델의 성능을 종합적으로 고려할 때, 랜덤포레스트가 1.0 클래스의 재현율과 F1-score에서 가장 좋은 성능을 보였다. 그리고 LGBM도 1.0 클래스에서의 재현율은 높게 나왔고 랜덤포레스트와 비슷한 성능을 보였다. 랜덤포레스트는 가장 높은 F1점수를 보였기에 본 분석에서 가장 적합한 분류 모델이라고 볼 수 있다
This post is licensed under CC BY 4.0 by the author.