채용플랫폼 이용패턴 분석 팀프로젝트9 - 가설 찾기
- 채용플랫폼 이용패턴 분석 팀프로젝트18 - 프로젝트 발표
- 채용플랫폼 이용패턴 분석 팀프로젝트17 - 보고서 및 PPT 마무리
- 채용플랫폼 이용패턴 분석 팀프로젝트16 - 보고서, PPT 초안 만들기2
- 채용플랫폼 이용패턴 분석 팀프로젝트15 - 보고서 초안 만들기
- 채용플랫폼 이용패턴 분석 팀프로젝트14 - A/B 테스트 체크리스트와 설계서 마무리
- 채용플랫폼 이용패턴 분석 팀프로젝트13 - A/B 테스트 체크리스트와 설계서 만들기
- 채용플랫폼 이용패턴 분석 팀프로젝트12 - 가설 검증 마무리 및 보고서 스토리라인 잡기
- 채용플랫폼 이용패턴 분석 팀프로젝트11-1 - 주말 회의
- 채용플랫폼 이용패턴 분석 팀프로젝트11 - 가설 검증
- 채용플랫폼 이용패턴 분석 팀프로젝트10 - 퍼널 재조정 및 가설 찾기2
- 채용플랫폼 이용패턴 분석 팀프로젝트8 - 데이터 이슈 발생
- 채용플랫폼 이용패턴 분석 팀프로젝트7 - Funnel 관점에서 로그분석2
- 채용플랫폼 이용패턴 분석 팀프로젝트6 - Funnel 관점에서 로그분석
- 채용플랫폼 이용패턴 분석 팀프로젝트5 - 유저 이용 패턴 파악
- 채용플랫폼 이용패턴 분석 팀프로젝트4 - 주제 선정
- 채용플랫폼 이용패턴 분석 팀프로젝트3 - 주제 변경
- 구독서비스 프로덕트데이터 분석 팀프로젝트2 - 분석할 수 있는 주제 찾아보기
- 구독서비스 프로덕트데이터 분석 팀프로젝트1 - 첫번째 팀활동 및 주제찾기
최종 분석 주제 : 채용 플랫폼 구직자 이탈 감소를 위한 검색 필터 A/B 테스트 제안
오늘 할 일
- 가설 수립 및 검증 : 전환율을 개선하고싶은 퍼널 선택 후 가설 설정해보기 (계속)
- 사용할 데이터 범위 정하기
- 퍼널 설정 재검토 (필요시)
- 가설 설정해보기
- 사용할 데이터 범위 정하기
오늘 한 일
- 사용할 데이터 범위 정하기 : 로그데이터와 로그데이터 외 데이터 테이블 간 추적 가능 부분 찾기
- 퍼널 재설정 : 추적 가능 데이터 관점에서 적절한 퍼널 재설정
- 가설 수립 및 검증 : 재설정한 퍼널에서 개선하고싶은 여정에 대한 가설 수립 및 검증
내일 할 일
- 가설 재수립 및 검증 : 전환율을 개선하고싶은 퍼널 선택 후 가설 설정해보기 (계속)
Issues & Challenges
사용할 데이터 범위 정하기 및 퍼널 재설정
- 로그데이터와 로그데이터 외 데이터 테이블 간 추적 가능 부분 찾기
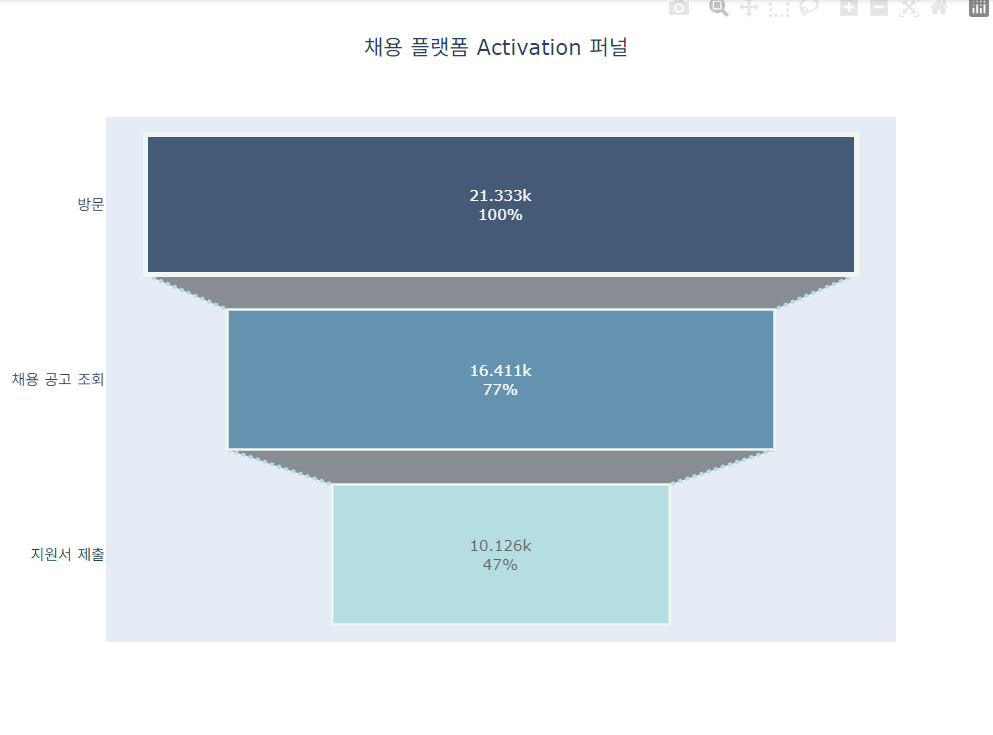
- 기존 설정한 퍼널 : 방문 → 채용 공고 조회 → 지원서 입력 → 지원서 제출
- 전환율을 개선하고싶은 여정 : 채용 공고 조회 → 지원서 입력
- 문제점
지원서 입력로그데이터를 로그데이터 외 데이터셋에서 추적 불가함- 따라서, 지원서 입력 관점에서는 로그데이터에서만 분석을 진행해야함
- 대안
지원서 제출로그데이터는 로그데이터 외 데이터셋에서 추적 가능함- 일부 싱크가 맞지않지만 전처리로 필터링 가능한 수준
- 약 1만명의 유저수 중 200명 정도 유저수가 존재하지 않음
- 조치사항
지원서 입력관점에서지원서 제출관점으로 분석방향 전환- 좀 더 넓은 범위의 가설 설정을 위해 퍼널 재설정 진행
- 변경 전 : 방문 → 채용 공고 조회 → 지원서 입력 → 지원서 제출
- 변경 후 : 방문 → 채용 공고 조회 → 지원서 제출
가설 수립 및 검증 : 재설정한 퍼널에서 개선하고싶은 여정에 대한 가설 수립 및 검증
- 데이터 범위 : 전체 데이터셋
- 가설 설정
- 구직자의 채용 공고 조회 수 증가할수록 지원서 제출 비율이 높을 것이다.
- 구직자가 채용 공고 북마크를 많이 할수록 지원서 제출 비율이 높을 것이다.
- 기업의 정보(회사정보, 주소, 투자, 인지도 등)가 많을수록 지원서 제출 비율이 높을 것이다.
- 월별 ‘신입’ 채용 공고가 많을수록 지원서 제출 비율이 높을 것이다
- 기본 이력서 작성 완료한 유저일수록 지원서 제출 비율이 올라갈 것이다.
- 기업의 투자 유치금이 많을수록 지원서 제출 비율이 높을 것이다.
- 월별 채용 공고 수가 많을수록 지원서 제출 비율이 높을 것이다.
- 채용 공고 수가 많은 직군의 지원서 제출 비율이 가장 높을 것이다.
- 관심도와 지원서 제출 비율에 상관관계가 있을 것이다.
- 관심도에 따른 지원서 제출 빈도는 정규분포를 따르지 않을 것이다.
- 구직자의 성향에 따라 지원서 제출에 도달하는 시간이 유의미한 차이가 있을것이다.
- 시스템 에러가 증가할수록 지원서 제출 비율이 낮을 것이다.
- 채용 공고 조회에서 지원서 제출 단계로 전환된 유저의 평균 시스템 에러 수보다 이탈한 유저의 평균 시스템 에러 수가 더 많을 것이다.
이슈사항
- 1차 이슈
지원서 제출 비율과지원서 제출에 싱크가 맞지않음- 지원서 제출 : 지원서 제출에 도달한 유저수 / 채용 공고 조회에 도달한 유저수
- 지원서 제출 비율 : 유저별 (지원서 제출수 / 채용공고조회수)의 평균
- 차이점 :
지원서 제출 비율에지원서 제출수와채용공고조회수가 추가됨- 기존의 유저수 기준에서 특정 행동의 횟수가 추가되어 방향성이 일치한다 볼수없음
- 퍼널 관점에서
지원서 제출이탈률과 가설 설정에서지원서 제출 비율의 관계 확인필요
- 조치사항 :
- 전체 데이터셋에서 진행이 안되고있어 지금까지했던 로그데이터 기준으로 분석 진행
- 데이터 범위 축소 : 전체 데이터셋 → 로그데이터
- 로그데이터와 퍼널 관점에서 가설 설정해보기
- 2차 이슈 : 로그데이터와 퍼널 관점에서 설정한 가설도 원활하게 검증작업을 할 수 없음
- 설정한 가설 : step3가 없는 채용공고와 step3가 있는 채용공고의 이탈율 차이가 있다
- 채용공고의 지원단계가 step1 ~ step4까지 있는데, step3는 필수 단계가 아님
- 따라서, 추가 지원단계가 있다면 이탈요인도 증가할 가능성이 있을수 있다
- 문제점 : 로그데이터 상 step3가 존재하는 공고인지 아닌지 확인할 수 없음
- 조치사항 : 분석이 불가능한 가설을 설정한것으로 판단하여 가설 삭제
- 설정한 가설 : step3가 없는 채용공고와 step3가 있는 채용공고의 이탈율 차이가 있다
- 향후 과제 : 분석이 가능한 가설 설정을 다시한번 고민해보자
- 발버둥 흔적들…


Reflection
- 로그데이터를 역추적하는데 성공했으나, 이제 분석 시작이라는것을 깨닫는데 오래걸리지 않았다. 로그데이터와 로그 외 데이터셋의 추적가능한
지원서 제출로그를 찾았음에도 원활하게 분석이 진행되고있지 않았다. 검증할 수 있는 가설들만 뽑는다는것도 어려움이 있다는것을 잘 알지만 검증할 수 없는 가설들만 나오고있어 지치는부분이 발생하고있다. 가설을 설정했을 당시에는 충분히 분석가능하다고 판단이 들다가도 막상 설정한 가설에서 어떤 데이터를 살펴봐야하는지 생각했을때 명확하게 매칭되지 않는다. 오히려 팀원들의 의견이 나오면서 가능할것같은 가설들이 불가능한 분석이라는것이 검증되고있었다. 설정한 여러가지의 가설들이 불가능하다는 것을 검증하는것도 반복되다보니 아이러니하게도 팀원들의 분석 레벨은 올라가고 있었다. 불가능하다는 것조차 모른다면 엉뚱한 분석결과가 나왔을테니… 지난 1주차와달리 굉장히 불확실하고 난항의 연속인 2주차의 흐름을 가지고있다. 불안하면서도 한걸음만 더 나아가면 다해결될것같은 느낌이 공존하고있다. 일단 가설을 계속 재수립할 계획이다. 이번주에 가설을 명확하게 설정할 수 있다면, 진행이 느리다고는 생각되지 않는다.
This post is licensed under CC BY 4.0 by the author.