공유오피스 출입데이터 분석 팀프로젝트4 - 데이터 전처리 및 모델링
최종 분석 주제 : 공유오피스 무료 체험 유저의 유료 결제 전환 예측 및 데이터 수집 전략 제안
오늘 할 일
- 데이터 전처리를 거쳐 모델링 적용해보기
오늘 한 일
- 데이터 전처리를 거쳐 모델링 적용해보기
내일 할 일
- 팀원과 모델링 결과 비교해보기
Issues & Challenges
논의사항
- (나) trial_visit_info 제외 파 vs (팀원) trial_visit_info 포함 파
- 제외 사유 : 1) site_area 에 있는 지점이 일부 없고, 없는 지점이 일부 있음

- (나) 고유유저수 기준 모델링 파 vs (팀원) 고유유저수 상관없이 모델링 파
- (나) 파생변수 필요 파 vs (팀원) 파생변수 필요 없다 파
- (내가 할 일) 어떤 고유유저수 기준으로 하는지?
- (내가 할 일2) 파생변수 어떤것들을 만들어야할지?
EDA와 전처리를 거쳐 모델링 적용해보기
- 데이터 전처리
- 결측치 확인
- 중복값 제거
- 전처리 및 파생변수 생성 및 데이터 결합
- 데이터 결합전
- TRIAL_REGISTER
- 체험신청일(평일/주말)
- 체험신청 요일
- 체험신청월
- 완료후 TRIAL_PAYMENT 테이블에 결합
- TRIAL_ACCESS_LOG (SITE_AREA 테이블과 결합)
- 데이터 전처리
- cdate 마이크로초 제거 및 +9시간 추가(trial_visit_info 테이블의 시간이 KST이므로 9시간 차이나는 것을 확인후 변환하였음)
- 비정상 체크인 검토 → 총 2,153개 행 감소
- 입실과 퇴실 갯수가 일치하지 않는 유저 : 1,762명
- 입실(1)로 시작하지 않거나 퇴실(2)로 끝나지 않는 유저 : 403명
- 1초간격으로 입실 혹은 퇴실 정보를 추가 (414건)
- 입실 또는 퇴실이 2번 이상 연속으로 나오는 경우 : 1,682명
- 입실(1)이 연속이면 마지막 데이터만 유지(앞단 입실 정보는 퇴실정보가 사라졌으므로 정확한 측정 불가)
- 퇴실(2)이 연속이면 첫번째 데이터만 유지(뒷단 퇴실 정보는 입실정보가 사라졌으므로 정확한 측정 불가)
- 2,567건 제거
- 파생변수 생성
- 총체류시간
- 일별 평균 체류시간
- 평일 체류시간
- 주말 체류시간
- 총입퇴실횟수
첫 방문 시간대(아침/오후/저녁) → 새벽 출입자 발생하여 삭제- 첫 방문 날짜(년-월-일)
- 주말 방문일 수
- 평일 방문일 수
- 가장 많이 방문한 지점id
- 가장 많이 방문한 지점의 면적
- 방문한 총 지점 수
- 데이터 전처리
- 데이터 결합 : TRIAL_ACCESS_LOG 고유 유저 수 기준으로 결합
- 분석 대상 : 무료체험 신청 후 공유 오피스를 실제로 방문한 유저
- TRIAL_ACCESS_LOG(방문) 고유 유저수 : 6,026명
- 결제 2,337명(39%), 미결제 3,689명(61%)
- TRIAL_PAYMENT(모든 무료체험 신청자) 고유 유저수 : 9,624명
- 결제 2,337명(24%), 미결제 7,287명(76%)
- 무료체험 신청후 미방문 유저(c - b) : 3,598명(37%)
- 방문 고유 유저수 선택 이유 :
- 미방문 유저가 약 37% 존재하고, 포함해서 분석하면 방문데이터 결측치 유저가 너무 많음
- 방문 유저 기준으로 하면 결제 비율은 약 39%로 데이터 불균형 문제가 없음
- 미방문 무료체험 유저는 방문 정보가 없어 예측 모델에 활용할 수 있는 변수가 제한적임
- 미방문 이유(외부요인, 개인사정 등)를 알 수 있는 데이터가 없어 분석이 제한적임
- 방문 패턴 기반으로 결제 가능성을 판단하는 데 더 집중할 수 있음
- 결과 활용 :
- 방문한 유저 중 결제 가능성이 높은 유저를 정의할 수 있음
- 방문 데이터를 기반으로 결제를 유도할 수 있는 전략(지점 최적화, 시간대 맞춤형 프로모션)을 제안할 수 있음
- TRIAL_REGISTER
- 데이터 결합후
- 파생변수 추가 : 체험신청후 첫방문까지 일수
- 외부데이터 찾아보기 : 분석이 추상적이지 않고 합리적인 외부데이터 찾아보기(날씨 등) : 나중에 해야지
- 데이터 결합전
- 범주형 데이터 인코딩
- 원-핫 인코딩 사용
- 데이터 불균형 여부를 고려하여 SMOTE 사용 고려 → 균형적임
- 데이터 전처리 및 결합 후 모델링 해보기
- 기존 학습한 모델링을 해볼지, AutoML, Bayesian Optimization, MLflow를 사용해볼지 고민해보기
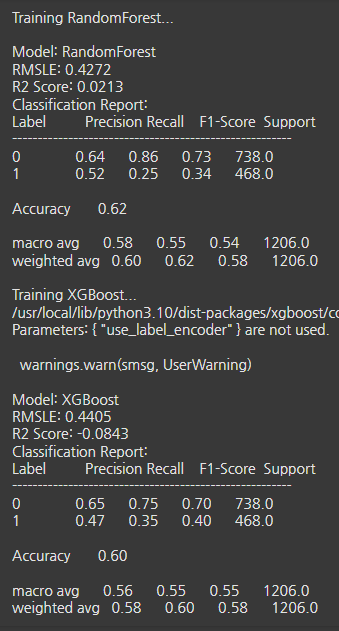
- 사용한 모델 : 랜덤 포레스트, XGBoost, LightGBM, CatBoost
- 튜닝전 베이스라인 모델 평가 지표
랜덤포레스트와 XGBoost
LightGBM과 CatBoost
Reflection
- 데이터가 크기도 작고 싱크도 맞지않아서 고민을하다 특정 테이블을 다른 테이블로 대체하고 풍부한 분석을 위해 파생변수를 생성했다. 출입로그가 2년 8개월치 데이터로 알고있는데, 전체 데이터를 제공받았는지는 모르겠지만 한달에 약 200명이 방문하는 공유오피스라니 안타깝다. 심지어 무료체험 신청자 중 방문조차 하지않은 유저가 37%나 된다. 아무래도 무료니까 가볍게 접근하는 유저도 많다고 생각한다. 그리고 이런 출입시스템은 동행 혹은 출입문이 오픈되어 있다면 출입정보가 부정확한 경우가 발생하는데, 현업에서는 어떤식으로 처리를 진행할지 궁금하다. 해당 유저의 정보를 버리자니 체류시간의 정보가 모델 예측에 중요할 것 같고, 살리자니 분석이 정확할 것 같지 않다. 그리고 클린한 유저 정보 또한 입실/퇴실을 연속적으로 안하는 경우가 있을수도있어 그어떤 정보도 신뢰할 수 없는 데이터가 된것같다. 데이터 분석은 알면 알수록 정확하다는 느낌을 못받는 것 같다. 이제는 데이터 기반 분석이 제일 정확한 논리라는 생각은 들지 않는다.
This post is licensed under CC BY 4.0 by the author.