공유오피스 출입데이터 분석 팀프로젝트5 - 모델 튜닝
최종 분석 주제 : 공유오피스 무료 체험 유저의 유료 결제 전환 예측 및 데이터 수집 전략 제안
오늘 할 일
- 데이터 모델링 하이퍼파라미터 튜닝
- 팀원과 모델링 결과 비교해보기
오늘 한 일
- 데이터 모델링 하이퍼파라미터 튜닝
- 팀원과 모델링 결과 비교해보기
내일 할 일
- 오전까지 모델링 개선 작업해서 팀원과 공유 → 제일 성능 좋은 코드 사용하기
- 결제 전환 재현율 개선 :
- 클래스 가중치, SMOTE, 다중공선성 확인 필요
- 추가 EDA해서 불필요한 파생변수 제거 필요
- 결제 전환 재현율 개선 :
- 오후부터 보고서 초안 작성 시작하기
Issues & Challenges
하이퍼파라미터 튜닝
변수 중요도 확인 : 체류시간과 첫 방문일이 중요한 변수로 작용
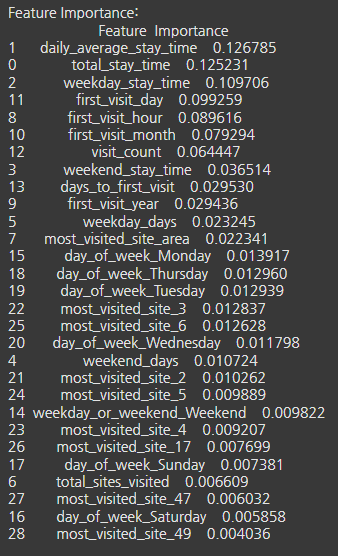
- 중요한 변수 선택 전/후 랜덤포레스트 성능 비교
- 피처 선택 전/후 성능이 큰 차이가 없음
- 하이퍼파라미터 튜닝후 피처 선택 고려 : 중요하게 생각하지 않은 변수가 중요해질 수 있기 때문
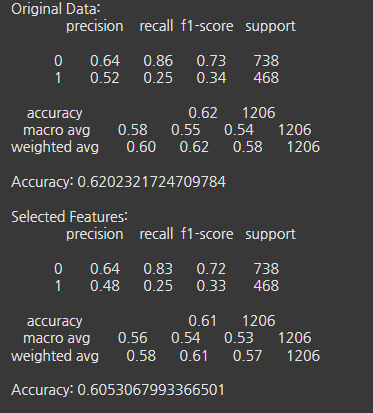
- 하이퍼파라미터 튜닝
- 교차검증 3-Fold 사용 (데이터 크기가 6026행으로 작음)
- Optuna를 사용하여 주요 파라미터 최적화
- Precision-Recall AUC 및 ROC AUC 평가 지표 추가
- 튜닝 결과
- 미결제 예측(재현율)은 높은편 0.85 이상
- 결제 전환 예측(재현율)이 낮음
- CatBoost는 1.00으로 과대 예측하는 경향이 있음
- 결제 전환 재현율 개선 필요 :
- 클래스 가중치, SMOTE, 다중공선성 확인 필요
- 추가 EDA해서 불필요한 파생변수 제거 필요
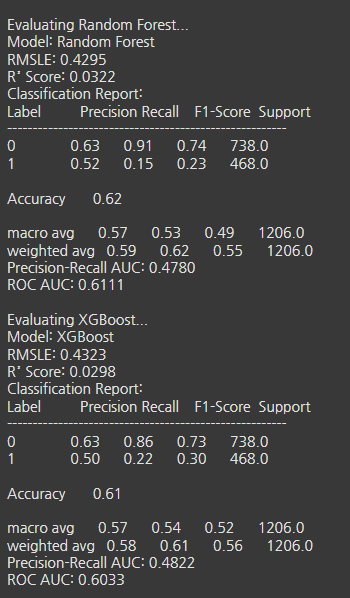
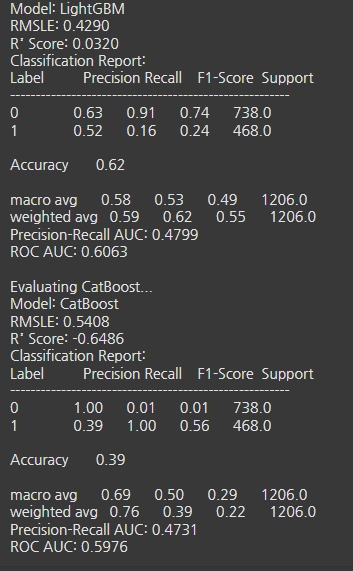
논의사항
- 모델링은 고유 유저 수 기준으로 해야하나? = 목표변수(TARGET)은 고유 유저 기준으로 해야하나?
- 그래야 할 것 같다. 왜냐하면 데이터 결합후 유저데이터가 고유 유저 수가 아닌 데이터로 크기가 커진다면, 모델링에서 유저ID를 변수로 선택하지 않기 때문에 모델이 학습할 때 TARGET별 고유 CASE인지 중복 CASE인지 판별을 못하고 고유로 인식하기에 과적합이 발생될 것. 따라서 모델링 데이터는 TARGET별 고유 ID 기준으로 모델링을 하는것이 정확할 것. → 고유 유저 수 기준으로 모델링 하기로 결정
- 파생변수 생성이 필요한가?
- 주어진 데이터에서 파생변수로 풀면 유의미한 인사이트를 얻을 수 있는 부분도 있을것. 데이터분석가는 데이터를 가지고 인사이트를 도출하는 직업으로 데이터셋도 결국 사람이 만든 변수기 때문에 파생변수 또한 사람이 유의미한 데이터를 얻기위해 만드는 행위라고 생각함. → 파생변수 생성하기로 결정
내일 할 일
- 오전까지 각자 고유유저수+파생변수 기준으로 모델링 개선 작업해서 팀원과 공유 → 제일 성능 좋은 코드 사용하기
- 결제 전환 재현율 개선 :
- 클래스 가중치, SMOTE, 다중공선성 확인 필요
- 추가 EDA해서 불필요한 파생변수 제거 필요
- 결제 전환 재현율 개선 :
- 오후부터 보고서 초안 작성 시작하기
Reflection
- 데이터셋을 가지고 전처리부터 모델링, 하이퍼파라미터 튜닝까지 한사이클을 수행하였고, 시간이 오래걸렸지만 이해를 하면서 완성을 시켜 만족스럽다. 비록, 모델 성능은 제대로 안나왔지만 이부분은 파생변수 생성후 EDA없이 모델 변수 선택에서 제외없이 진행해서 그런것같다. 개인적으로 이번 프로젝트에서 원하는 목표를 논리적으로 만들어 볼 수 있어서 성능은 안좋더라도 이해를 기반으로 진행하여 만족스럽다. 시간관계상 얼마나 많은 작업을 할 수 있을지 모르겠지만 일단 진행해보자.
This post is licensed under CC BY 4.0 by the author.