Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following NEW packages will be installed:
fonts-nanum
0 upgraded, 1 newly installed, 0 to remove and 49 not upgraded.
Need to get 10.3 MB of archives.
After this operation, 34.1 MB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu jammy/universe amd64 fonts-nanum all 20200506-1 [10.3 MB]
Fetched 10.3 MB in 0s (39.8 MB/s)
debconf: unable to initialize frontend: Dialog
debconf: (No usable dialog-like program is installed, so the dialog based frontend cannot be used. at /usr/share/perl5/Debconf/FrontEnd/Dialog.pm line 78, <> line 1.)
debconf: falling back to frontend: Readline
debconf: unable to initialize frontend: Readline
debconf: (This frontend requires a controlling tty.)
debconf: falling back to frontend: Teletype
dpkg-preconfigure: unable to re-open stdin:
Selecting previously unselected package fonts-nanum.
(Reading database ... 123599 files and directories currently installed.)
Preparing to unpack .../fonts-nanum_20200506-1_all.deb ...
Unpacking fonts-nanum (20200506-1) ...
Setting up fonts-nanum (20200506-1) ...
Processing triggers for fontconfig (2.13.1-4.2ubuntu5) ...
/usr/share/fonts: caching, new cache contents: 0 fonts, 1 dirs
/usr/share/fonts/truetype: caching, new cache contents: 0 fonts, 3 dirs
/usr/share/fonts/truetype/humor-sans: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/liberation: caching, new cache contents: 16 fonts, 0 dirs
/usr/share/fonts/truetype/nanum: caching, new cache contents: 12 fonts, 0 dirs
/usr/local/share/fonts: caching, new cache contents: 0 fonts, 0 dirs
/root/.local/share/fonts: skipping, no such directory
/root/.fonts: skipping, no such directory
/usr/share/fonts/truetype: skipping, looped directory detected
/usr/share/fonts/truetype/humor-sans: skipping, looped directory detected
/usr/share/fonts/truetype/liberation: skipping, looped directory detected
/usr/share/fonts/truetype/nanum: skipping, looped directory detected
/var/cache/fontconfig: cleaning cache directory
/root/.cache/fontconfig: not cleaning non-existent cache directory
/root/.fontconfig: not cleaning non-existent cache directory
fc-cache: succeeded
1
2
3
4
5
6
7
8
9
10
11
12
# ▶ 한글 폰트 설정하기
importmatplotlib.pyplotaspltplt.rc('font',family='NanumBarunGothic')plt.rcParams['axes.unicode_minus']=False# ▶ Warnings 제거
importwarningswarnings.filterwarnings('ignore')# ▶ Google drive mount or 폴더 클릭 후 구글드라이브 연결
fromgoogle.colabimportdrivedrive.mount('/content/drive')
1
Mounted at /content/drive
1
2
3
4
5
6
7
8
9
10
11
12
13
14
##########################################
### 한글이 깨지는 경우 아래 코드 실행하기 !!!###
##########################################
importmatplotlib.pyplotaspltimportmatplotlib.font_managerasfm# 나눔고딕 폰트를 설치합니다.
!apt-getinstall-yfonts-nanum!fc-cache-fv# 설치된 나눔고딕 폰트를 matplotlib에 등록합니다.
font_path='/usr/share/fonts/truetype/nanum/NanumGothic.ttf'fm.fontManager.addfont(font_path)plt.rcParams['font.family']='NanumGothic'
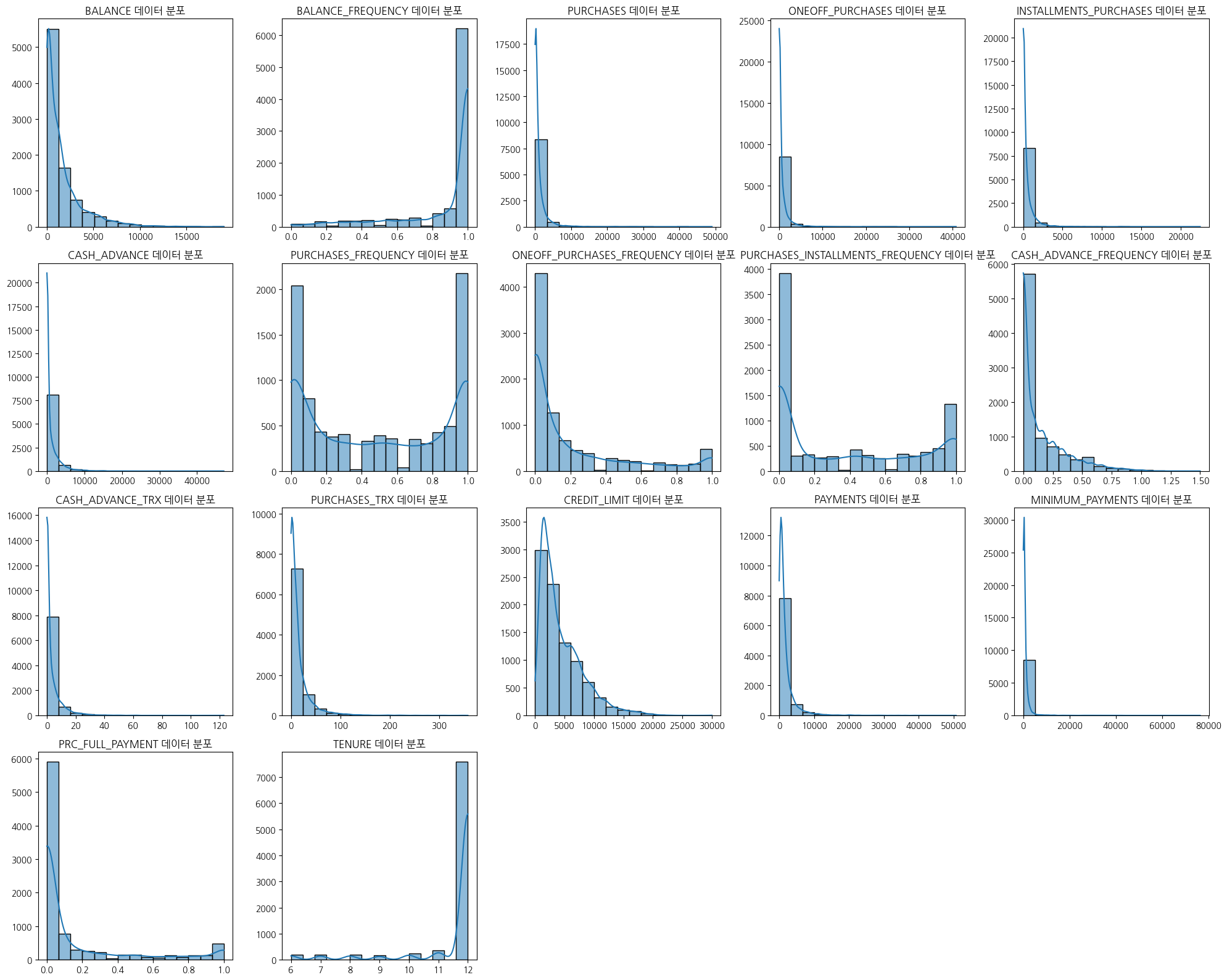
plt.figure(figsize=(20,16))forindex,colinenumerate(numeric_columns):plt.subplot(4,5,index+1)sns.histplot(numeric_columns[col],bins=15,kde=True)plt.title(f"{col} 데이터 분포")plt.xlabel('')plt.ylabel('')plt.tight_layout()plt.show()
1
# 전체데이터로는 대부분 한쪽으로 치우쳐진 형태를 보이고 있다
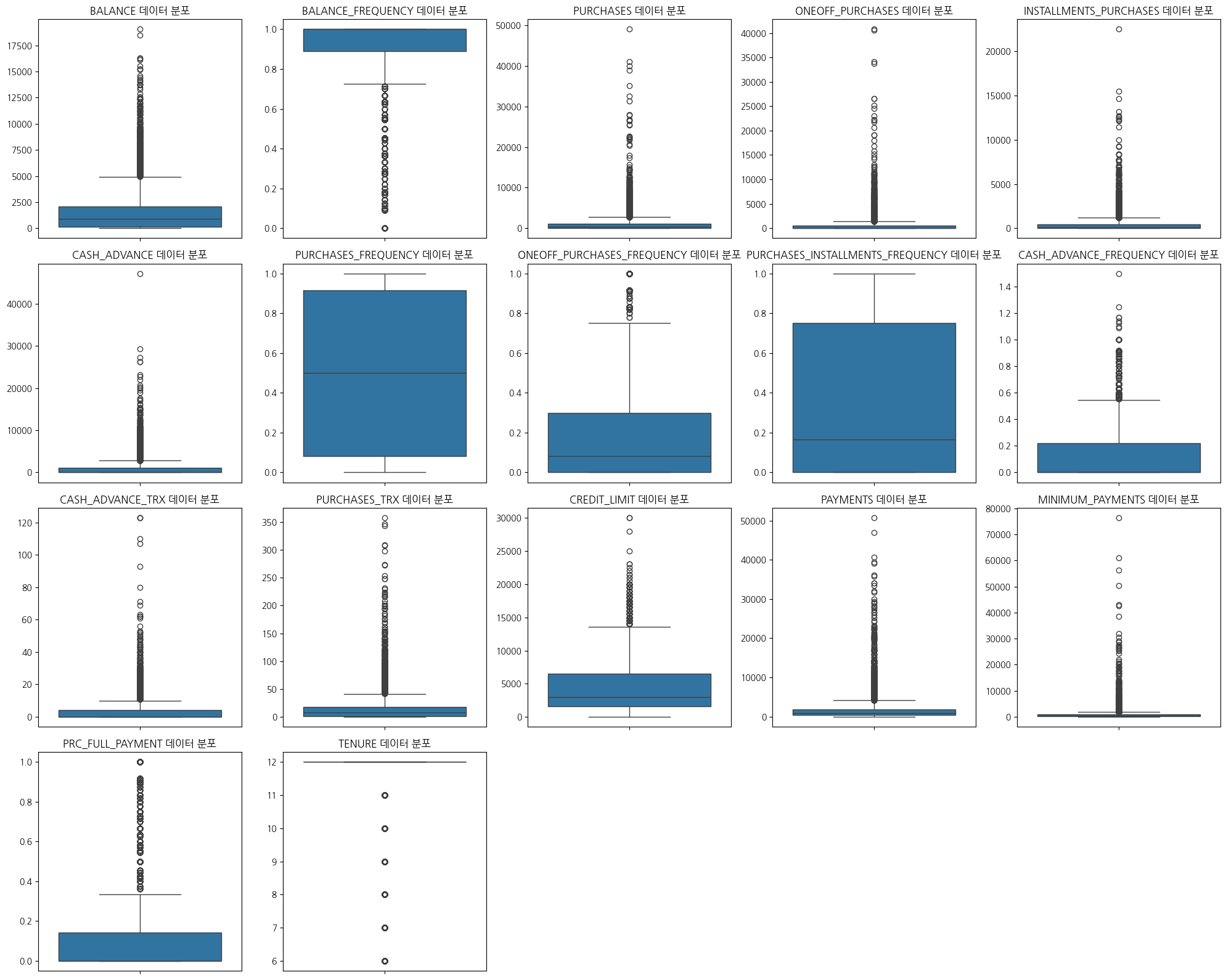
문제6: 데이터의 이상치 파악하기
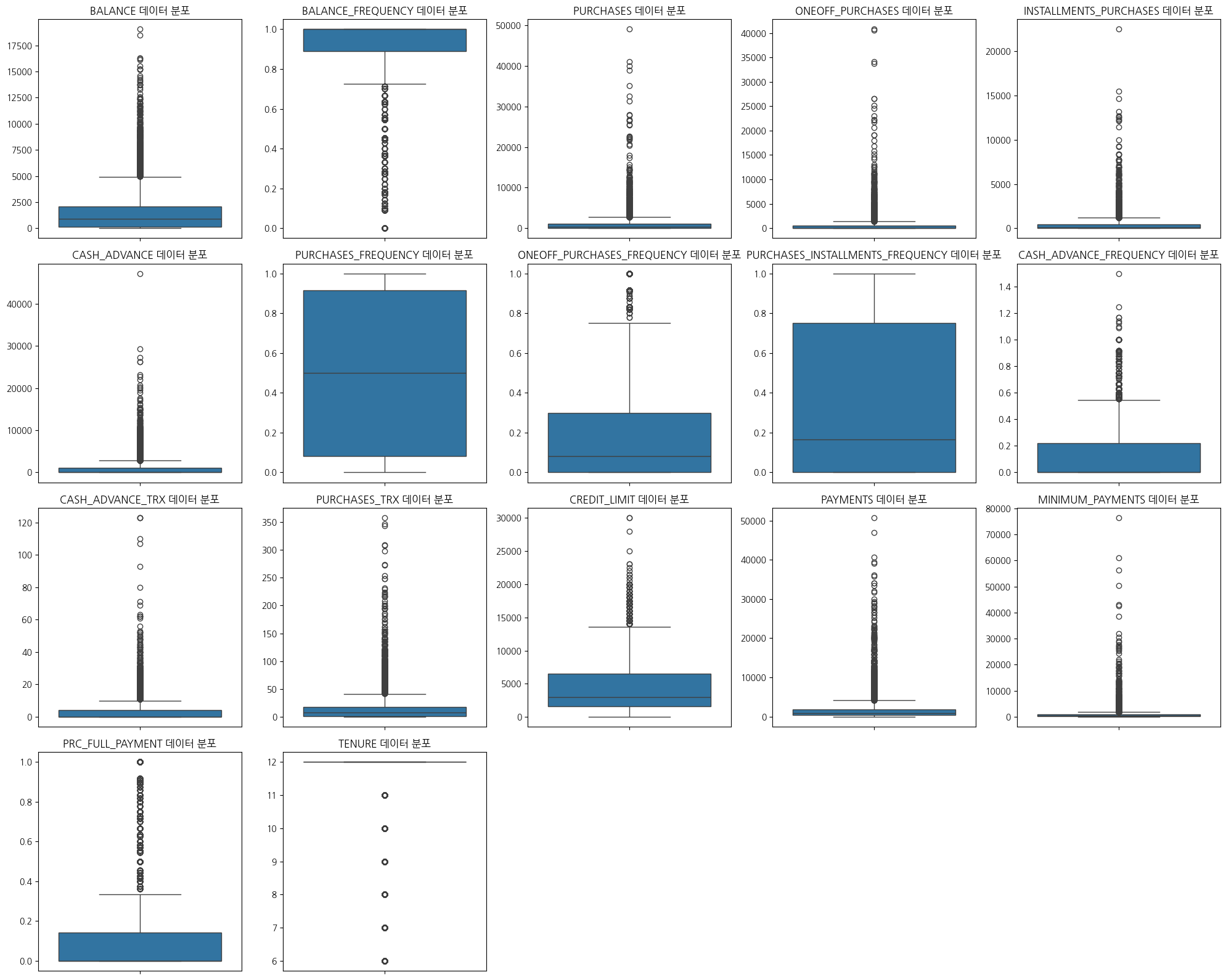
데이터의 이상치를 파악하세요. 이를 위해 각 변수의 분포를 상자 그림으로 시각화하세요.
1
2
3
4
5
6
7
8
9
10
plt.figure(figsize=(20,16))forindex,colinenumerate(numeric_columns):plt.subplot(4,5,index+1)sns.boxplot(data=numeric_columns,y=col)plt.title(f"{col} 데이터 분포")plt.xlabel('')plt.ylabel('')plt.tight_layout()plt.show()
1
# 금수저들에의해 이상치가 무수히 발생하고있다
데이터 전처리 (3문제)
문제7: 결측치 처리하기
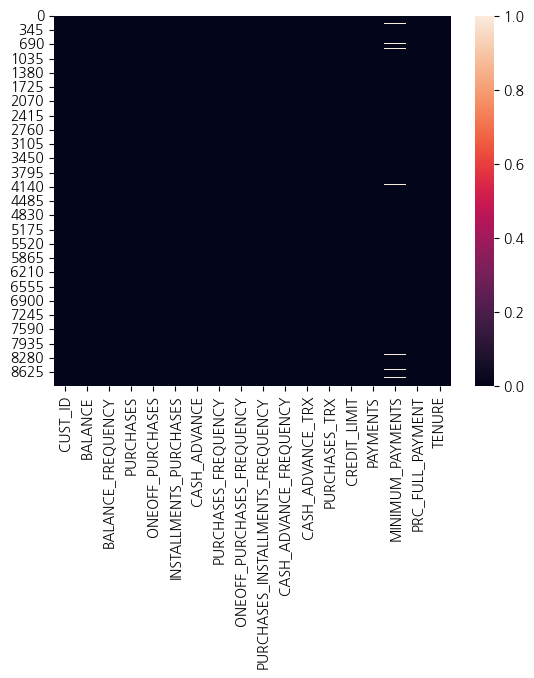
변수의 결측치 수를 확인하고, 결측치가 존재하는 변수들을 적절한 방법으로 전처리하세요.
1
2
3
data2=numeric_columnsdata2.isna().sum().sort_values(ascending=False)# 최소 지불액 변수에서 313개 결측치, 신용 한도에서 1개 결측치 관찰됨
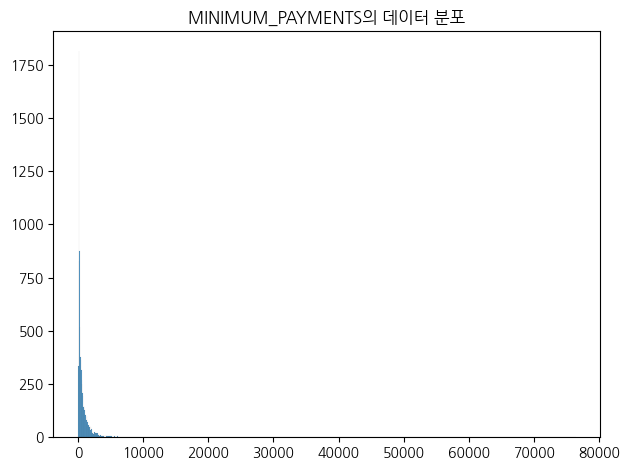
# 최소 지불액 시각화 : 75%가 825인데 max값이 76406이다. 결측치는 중앙값처리가 더 적절해보인다.
sns.histplot(data2['MINIMUM_PAYMENTS'])plt.title("MINIMUM_PAYMENTS의 데이터 분포")plt.xlabel('')plt.ylabel('')plt.tight_layout()plt.show()
1
2
# 최소지불액과 지불액 관계 : 최소지불액 결측치가 지불액에서 어떻게 나타나는지 확인
data2['PAYMENTS'][data2['MINIMUM_PAYMENTS'].isna()].value_counts().sort_values(ascending=False)
count
PAYMENTS
0.000000
240
432.927281
1
746.691026
1
1159.135064
1
29272.486070
1
...
...
295.937124
1
3905.430817
1
5.070726
1
578.819329
1
275.861322
1
74 rows × 1 columns
1
2
3
4
5
6
7
8
9
10
11
12
13
# 최소지불액 결측치 처리
# 1) 지불액 변수값이 0이다 : 최소지불액 결측치도 0으로 처리
# 2) 지불액 변수값이 0이 아니다 : 최소지불액 결측치 중앙값 처리
median_minimum_payments=data2['MINIMUM_PAYMENTS'].median()forindex,rowindata2.iterrows():ifpd.isnull(row['MINIMUM_PAYMENTS']):ifrow['PAYMENTS']==0:data2.at[index,'MINIMUM_PAYMENTS']=0else:data2.at[index,'MINIMUM_PAYMENTS']=median_minimum_paymentsdata2.isna().sum().sort_values(ascending=False)
0
BALANCE
0
CASH_ADVANCE_FREQUENCY
0
PRC_FULL_PAYMENT
0
MINIMUM_PAYMENTS
0
PAYMENTS
0
CREDIT_LIMIT
0
PURCHASES_TRX
0
CASH_ADVANCE_TRX
0
PURCHASES_INSTALLMENTS_FREQUENCY
0
BALANCE_FREQUENCY
0
ONEOFF_PURCHASES_FREQUENCY
0
PURCHASES_FREQUENCY
0
CASH_ADVANCE
0
INSTALLMENTS_PURCHASES
0
ONEOFF_PURCHASES
0
PURCHASES
0
TENURE
0
1
2
3
4
# 추가 점검 : 총 지불액이 최소지불액보다 작을수있을까?
payment_check=data2[data2['MINIMUM_PAYMENTS']>data2['PAYMENTS']]print(f"최소지불액보다 작은 총 지불액 개수 : {payment_check.shape[0]}")print(f"전체 데이터 중 약 {round((payment_check.shape[0])/(data2.shape[0])*100)}%에서 발견됨")
1
2
최소지불액보다 작은 총 지불액 개수 : 2397
전체 데이터 중 약 27%에서 발견됨
1
payment_check[['MINIMUM_PAYMENTS','PAYMENTS']]
MINIMUM_PAYMENTS
PAYMENTS
2
627.284787
622.066742
5
2407.246035
1400.057770
10
2172.697765
1083.301007
14
989.962866
805.647974
15
2109.906490
1993.439277
...
...
...
8939
110.950798
72.530037
8946
312.452292
275.861322
8947
82.418369
81.270775
8948
55.755628
52.549959
8949
88.288956
63.165404
2397 rows × 2 columns
1
2
3
4
5
6
7
8
9
10
11
# 총 지불액이 최소 지불액보다 작은경우?
# 1) 환불발생 : 현재데이터로 확인불가
# 2) 할인발생 : 현재데이터로 확인불가
# 3) 할부구매 : INSTALLMENTS_PURCHASES, PURCHASES_INSTALLMENTS_FREQUENCY의 값이 0보다 크다면 할부금액으로 인한 지불액 차이가 고려될 수 있다.
# 4) 신용한도 초과 : CREDIT_LIMIT에 영향을 받을수있다. 신용한도가 낮아 최소 결제 금액을 충족하지 못한 경우.
# 5) 미지급 : 신용카드 결제일에 고객이 전액을 지급하지 않거나 일부만 납부한 경우. 현재데이터로 확인불가
# 6) 현금서비스 : CASH_ADVANCE, CASH_ADVANCE_FREQUENCY의 값이 0보다 크다면 고려될 수 있다.
# 7) 기타 : 시스템오류나 고객의 단순 지불액 착각, 돌려막기 등...
# 하지만 현재데이터상으로는 이상치로 판단하기에는 너무많은 데이터가 소실될 위험이 있다.
# 주어진 데이터의 한계로 위와같은 데이터가 제공되지 않아 비정상적으로 보일 수 있다고 판단하여 이상치를 제거하지 않음.
문제8: 이상치 처리하기
데이터에 이상치가 있는지 확인해보세요. 확인 후, 전처리가 필요하다면 진행해주세요.
1
2
3
4
5
6
7
8
9
10
11
12
13
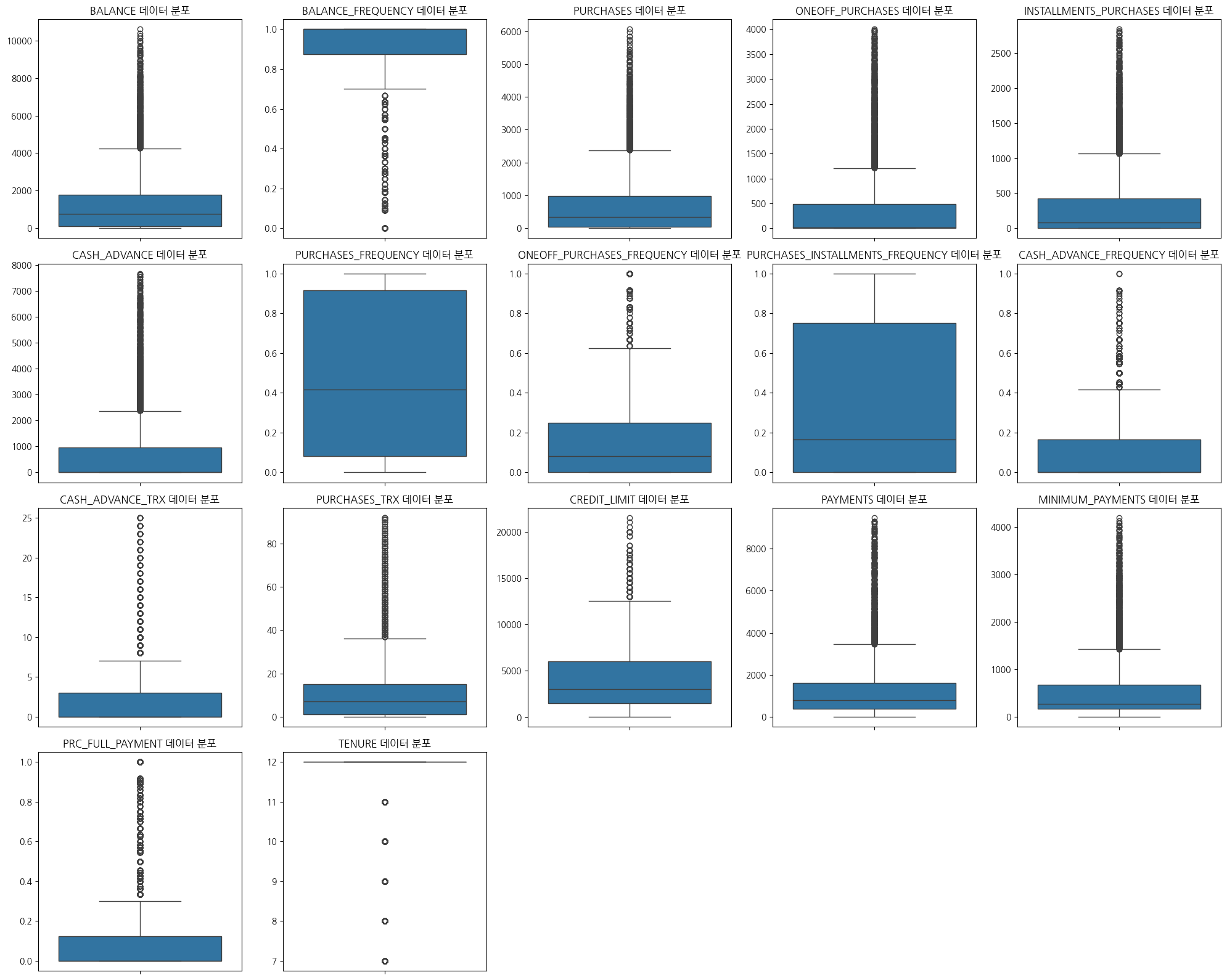
# 이상치 제거 전 시각화
data3=data2.copy()plt.figure(figsize=(20,16))forindex,colinenumerate(data3):plt.subplot(4,5,index+1)sns.boxplot(data=data3,y=col)plt.title(f"{col} 데이터 분포")plt.xlabel('')plt.ylabel('')plt.tight_layout()plt.show()
1
2
3
4
# 이상치가 너무 많다 : 다양한방법으로 시도해보자
# 1. IQR기준 이상치 처리
# 2. IQR 0.10 ~ 0.90 기준 이상치 처리
# 3. 특정변수만 이상치처리
# 이상치 제거 (전처리 진행)
data4=data2.copy()defget_outlier_mask(df,weight=1.5):Q1=df.quantile(0.25)Q3=df.quantile(0.75)IQR=Q3-Q1IQR_weight=IQR*weightrange_min=Q1-IQR_weightrange_max=Q3+IQR_weightoutlier_per_column=(df<range_min)|(df>range_max)is_outlier=outlier_per_column.any(axis=1)returnis_outlieroutlier_idx_cust_df=get_outlier_mask(data4,weight=1.5)# 이상치를 제거한 데이터 프레임만 추가
data4=data4[~outlier_idx_cust_df]data4
BALANCE
BALANCE_FREQUENCY
PURCHASES
ONEOFF_PURCHASES
INSTALLMENTS_PURCHASES
CASH_ADVANCE
PURCHASES_FREQUENCY
ONEOFF_PURCHASES_FREQUENCY
PURCHASES_INSTALLMENTS_FREQUENCY
CASH_ADVANCE_FREQUENCY
CASH_ADVANCE_TRX
PURCHASES_TRX
CREDIT_LIMIT
PAYMENTS
MINIMUM_PAYMENTS
PRC_FULL_PAYMENT
TENURE
0
40.900749
0.818182
95.40
0.00
95.40
0.000000
0.166667
0.000000
0.083333
0.000000
0
2
1000.0
201.802084
139.509787
0.000000
12
4
817.714335
1.000000
16.00
16.00
0.00
0.000000
0.083333
0.083333
0.000000
0.000000
0
1
1200.0
678.334763
244.791237
0.000000
12
7
1823.652743
1.000000
436.20
0.00
436.20
0.000000
1.000000
0.000000
1.000000
0.000000
0
12
2300.0
679.065082
532.033990
0.000000
12
8
1014.926473
1.000000
861.49
661.49
200.00
0.000000
0.333333
0.083333
0.250000
0.000000
0
5
7000.0
688.278568
311.963409
0.000000
12
14
2772.772734
1.000000
0.00
0.00
0.00
346.811390
0.000000
0.000000
0.000000
0.083333
1
0
3000.0
805.647974
989.962866
0.000000
12
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
8738
981.286008
1.000000
1370.00
1370.00
0.00
0.000000
0.083333
0.083333
0.000000
0.000000
0
1
1400.0
596.685481
451.584847
0.000000
12
8742
87.026009
1.000000
605.52
0.00
605.52
0.000000
1.000000
0.000000
0.916667
0.000000
0
12
1500.0
511.637312
175.012705
0.000000
12
8747
16.428326
0.909091
441.50
124.70
316.80
0.000000
1.000000
0.166667
0.916667
0.000000
0
14
1000.0
482.547848
91.328536
0.333333
12
8759
67.377243
1.000000
295.00
0.00
295.00
0.000000
0.500000
0.000000
0.416667
0.000000
0
6
1000.0
245.689379
167.126034
0.300000
12
8760
307.127754
1.000000
909.30
409.30
500.00
237.378894
0.583333
0.166667
0.500000
0.166667
4
12
1000.0
943.278170
179.258575
0.000000
12
2987 rows × 17 columns
1
2
3
4
# IQR기준으로 이상치를 처리하면 데이터가 33% 밖에 남지 않는다.
# 이번데이터는 마케팅 전략을 수립하기 위해 고객 세분화 방안을 찾는것이다.
# 그런데 전체 데이터를 67% 버리고 고객 세분화 방안을 찾는것은 원래목적의 의미가 퇴색될수있다.
# 다른방안을 선택하는것이 좋아보인다.
data6=data2.copy()defget_outlier_mask(df,columns,weight=1.5):# 선택한 열만 사용
df_selected=df[columns]Q1=df_selected.quantile(0.25)Q3=df_selected.quantile(0.75)IQR=Q3-Q1IQR_weight=IQR*weightrange_min=Q1-IQR_weightrange_max=Q3+IQR_weightoutlier_per_column=(df_selected<range_min)|(df_selected>range_max)is_outlier=outlier_per_column.any(axis=1)returnis_outlier# 이상치를 처리할 열 리스트
columns_to_check=['BALANCE','PURCHASES','ONEOFF_PURCHASES','INSTALLMENTS_PURCHASES','CASH_ADVANCE','CREDIT_LIMIT','PAYMENTS','MINIMUM_PAYMENTS']# 이상치 인덱스 생성
outlier_idx_cust_df=get_outlier_mask(data6,columns_to_check,weight=1.5)# 이상치를 제거한 데이터프레임 생성
data6=data6[~outlier_idx_cust_df]data6
BALANCE
BALANCE_FREQUENCY
PURCHASES
ONEOFF_PURCHASES
INSTALLMENTS_PURCHASES
CASH_ADVANCE
PURCHASES_FREQUENCY
ONEOFF_PURCHASES_FREQUENCY
PURCHASES_INSTALLMENTS_FREQUENCY
CASH_ADVANCE_FREQUENCY
CASH_ADVANCE_TRX
PURCHASES_TRX
CREDIT_LIMIT
PAYMENTS
MINIMUM_PAYMENTS
PRC_FULL_PAYMENT
TENURE
0
40.900749
0.818182
95.40
0.00
95.40
0.000000
0.166667
0.000000
0.083333
0.000000
0
2
1000.0
201.802084
139.509787
0.00
12
2
2495.148862
1.000000
773.17
773.17
0.00
0.000000
1.000000
1.000000
0.000000
0.000000
0
12
7500.0
622.066742
627.284787
0.00
12
4
817.714335
1.000000
16.00
16.00
0.00
0.000000
0.083333
0.083333
0.000000
0.000000
0
1
1200.0
678.334763
244.791237
0.00
12
7
1823.652743
1.000000
436.20
0.00
436.20
0.000000
1.000000
0.000000
1.000000
0.000000
0
12
2300.0
679.065082
532.033990
0.00
12
8
1014.926473
1.000000
861.49
661.49
200.00
0.000000
0.333333
0.083333
0.250000
0.000000
0
5
7000.0
688.278568
311.963409
0.00
12
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
8945
28.493517
1.000000
291.12
0.00
291.12
0.000000
1.000000
0.000000
0.833333
0.000000
0
6
1000.0
325.594462
48.886365
0.50
6
8946
19.183215
1.000000
300.00
0.00
300.00
0.000000
1.000000
0.000000
0.833333
0.000000
0
6
1000.0
275.861322
312.452292
0.00
6
8947
23.398673
0.833333
144.40
0.00
144.40
0.000000
0.833333
0.000000
0.666667
0.000000
0
5
1000.0
81.270775
82.418369
0.25
6
8948
13.457564
0.833333
0.00
0.00
0.00
36.558778
0.000000
0.000000
0.000000
0.166667
2
0
500.0
52.549959
55.755628
0.25
6
8949
372.708075
0.666667
1093.25
1093.25
0.00
127.040008
0.666667
0.666667
0.000000
0.333333
2
23
1200.0
63.165404
88.288956
0.00
6
5869 rows × 17 columns
1
2
# 특정변수만 이상치를 처리하면 66% 데이터가 남는다.
# 시각화를 통해 2번과 3번 방안중에 선택고려
1
2
3
4
5
6
7
8
9
10
11
12
# 이상치 제거 후 시각화
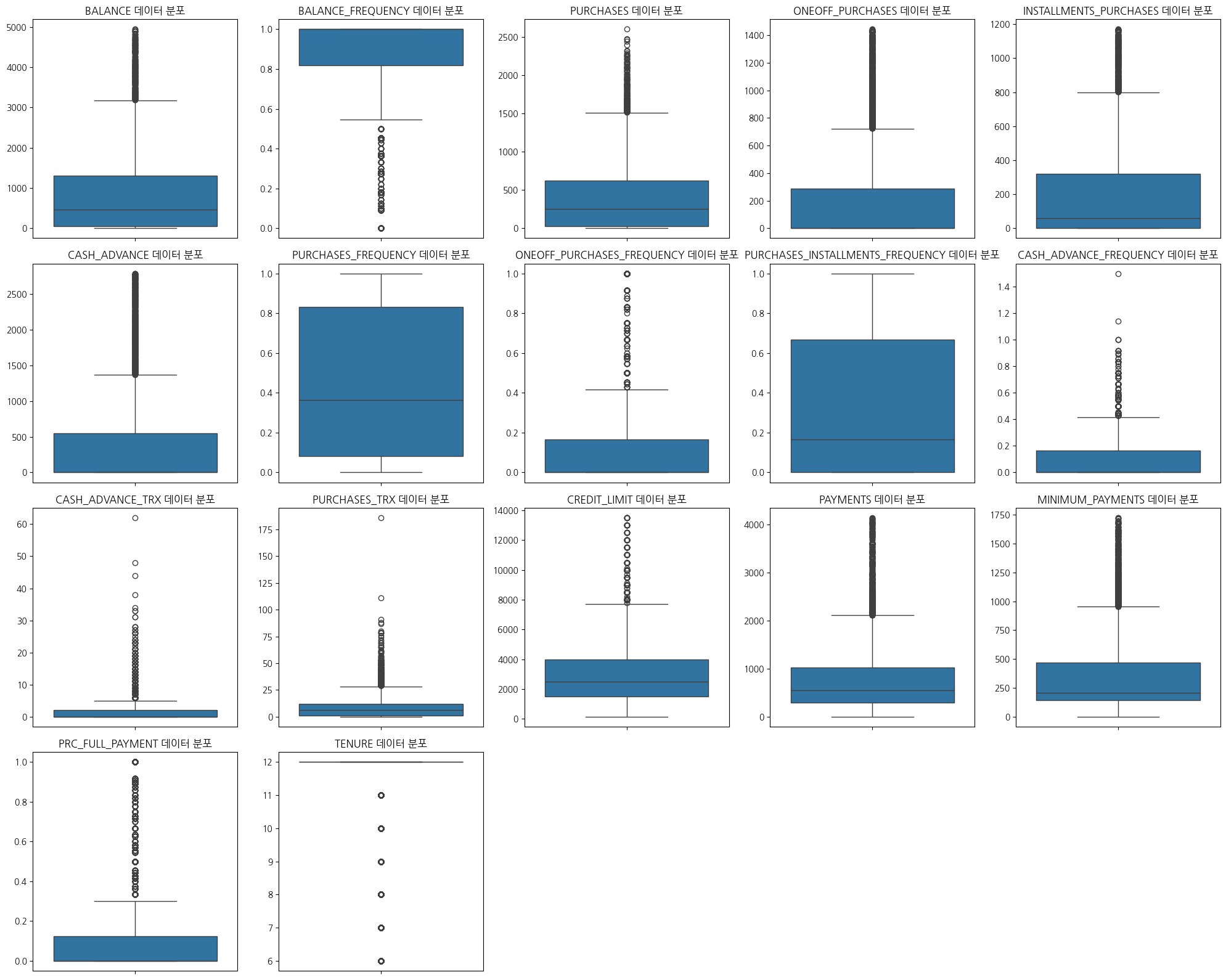
# 2. IQR 0.10 ~ 0.90 버전
plt.figure(figsize=(20,16))forindex,colinenumerate(data5):plt.subplot(4,5,index+1)sns.boxplot(data=data5,y=col)plt.title(f"{col} 데이터 분포")plt.xlabel('')plt.ylabel('')plt.tight_layout()plt.show()
1
# 이상치 제거 전 박스플롯과 비슷해보이지만, 전반적으로 변수별로 이상치들이 잘 모여있다.
1
2
3
4
5
6
7
8
9
10
11
12
# 3. 특정변수만 이상치 제거 버전
# max값이 많이 튀는 특정 변수만 이상치 처리 : BALANCE, PURCHASES, ONEOFF_PURCHASES, INSTALLMENTS_PURCHASES, CASH_ADVANCE, CREDIT_LIMIT, PAYMENTS, MINIMUM_PAYMENTS
plt.figure(figsize=(20,16))forindex,colinenumerate(data6):plt.subplot(4,5,index+1)sns.boxplot(data=data6,y=col)plt.title(f"{col} 데이터 분포")plt.xlabel('')plt.ylabel('')plt.tight_layout()plt.show()
1
2
# 2번 IQR 0.1 ~ 0.9 버전보다 3번 방식으로 선택한 변수들은 데이터가 더 잘모여있고, 선택되지않은 데이터들은 이상치가 조금 튀고있다.
# 우선, 2번 방식으로 데이터분석을 진행하되, 적절한 분석이 안될경우 2번 데이터를 추가적인 전처리를 취하거나 3번 데이터를 사용한다.
문제9: 데이터 스케일링하기
각 변수의 데이터를 표준화 혹은 정규화하세요.
1
2
3
4
5
6
7
8
data7=data5.copy()df_mean=data7.mean()# 각 컬럼의 평균값
df_std=data7.std()# 각 컬럼의 표준편차
scaled_df=(data7-df_mean)/df_std# 컬럼별 표준화 진행
scaled_df
BALANCE
BALANCE_FREQUENCY
PURCHASES
ONEOFF_PURCHASES
INSTALLMENTS_PURCHASES
CASH_ADVANCE
PURCHASES_FREQUENCY
ONEOFF_PURCHASES_FREQUENCY
PURCHASES_INSTALLMENTS_FREQUENCY
CASH_ADVANCE_FREQUENCY
CASH_ADVANCE_TRX
PURCHASES_TRX
CREDIT_LIMIT
PAYMENTS
MINIMUM_PAYMENTS
PRC_FULL_PAYMENT
TENURE
0
-0.759182
-0.215160
-0.647033
-0.562980
-0.438501
-0.554363
-0.781661
-0.655331
-0.686195
-0.681752
-0.583682
-0.642690
-0.963550
-0.757062
-0.619400
-0.519489
0.342764
1
1.133650
0.157721
-0.749808
-0.562980
-0.636448
4.353579
-1.201814
-0.655331
-0.899241
0.741303
0.340613
-0.777379
0.886997
2.054140
0.838968
0.253563
0.342764
2
0.710178
0.530603
0.083138
0.554513
-0.636448
-0.554363
1.319102
2.889269
-0.899241
-0.681752
-0.583682
0.030750
1.041209
-0.454222
0.143178
-0.519489
0.342764
3
0.214168
-0.960924
0.865084
1.603584
-0.636448
-0.397603
-0.991739
-0.359948
-0.899241
-0.207402
-0.352608
-0.710034
1.041209
-0.902479
-0.837506
-0.519489
0.342764
4
-0.294103
0.530603
-0.732571
-0.539855
-0.636448
-0.554363
-0.991739
-0.359948
-0.899241
-0.681752
-0.583682
-0.710034
-0.901865
-0.413676
-0.454805
-0.519489
0.342764
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
8908
-0.770882
0.530603
-0.520481
-0.562980
-0.194761
-0.554363
1.319102
-0.655331
1.292097
-0.681752
-0.583682
-0.305970
-0.963550
-0.780185
-0.675873
2.959249
-4.300677
8909
-0.399733
0.530603
0.058177
0.521025
-0.636448
-0.554363
-0.841684
-0.148960
-0.899241
-0.681752
-0.583682
-0.710034
-0.963550
-0.826397
-0.364203
-0.519489
-4.300677
8910
-0.570467
0.530603
-0.248858
0.109103
-0.636448
-0.554363
-0.841684
-0.148960
-0.899241
-0.681752
-0.583682
-0.710034
-0.963550
-0.816891
-0.666743
-0.519489
-4.300677
8911
-0.765283
-2.399186
-0.002778
-0.562980
0.802339
-0.554363
0.598841
-0.655331
0.561652
-0.681752
-0.583682
-0.305970
-0.963550
-0.070540
-0.812721
-0.519489
-4.300677
8912
-0.558230
-0.055354
-0.189605
-0.158285
-0.138469
0.343290
0.958971
-0.148960
0.926875
3.384121
1.495983
-0.305970
-0.963550
-0.232748
-0.675028
0.176258
-4.300677
7860 rows × 17 columns
표준화는 데이터의 평균을 0, 표준편차를 1로 맞추어 변환합니다.
정규화는 데이터 값을 0과 1 사이로 변환합니다.
표준화와 정규화는 모델 학습의 성능을 향상시킬 수 있습니다.
이후 분석은 표준화된 데이터를 바탕으로 진행하겠습니다.
클러스터 분석 (11문제)
###문제10: K-means 클러스터링 모델 학습
K-means 알고리즘을 사용하여 클러스터링 모델을 학습하세요. 클러스터의 수는 3로 설정하세요.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KMeans(n_clusters=3, random_state=21)
1
2
3
4
5
6
# 군집 레이블을 데이터프레임에 추가
data10['cluster']=model.predict(data10)# 군집별 데이터 개수 확인
cluster_counts=data10['cluster'].value_counts()cluster_counts
count
cluster
0
4610
1
1653
2
1597
문제11 : 클러스터링 결과 시각화 (2D)
두 개의 주요 변수(BALANCE, PURCHASES)를 사용하여 클러스터링 결과를 2D로 시각화하세요.
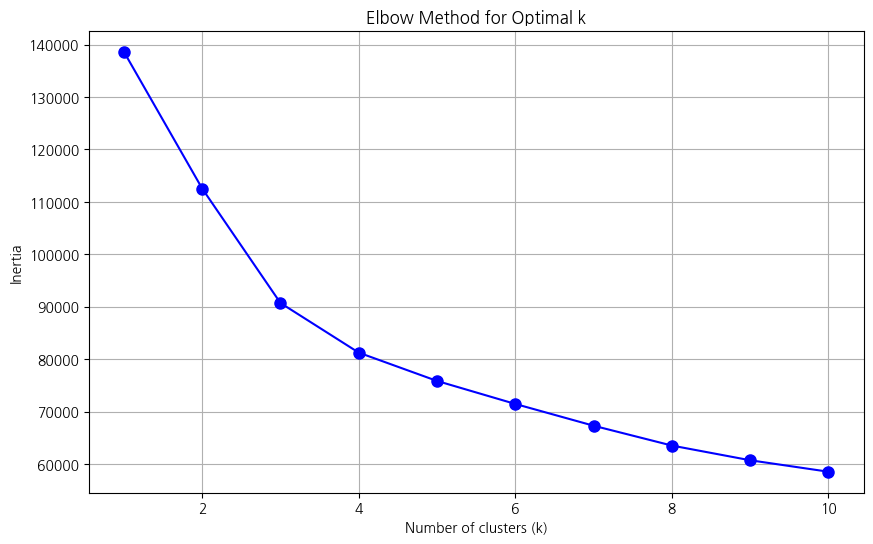
# 엘보우 기법을 위한 KMeans 모델 실행 및 inertia 계산
inertia_list=[]k_values=range(1,11)forkink_values:kmeans=KMeans(n_clusters=k,random_state=21)kmeans.fit(data10)inertia_list.append(kmeans.inertia_)# 각 k에 대한 inertia 저장
# 3. 엘보우 기법 시각화
plt.figure(figsize=(10,6))plt.plot(k_values,inertia_list,'bo-',markersize=8)plt.xlabel('Number of clusters (k)')plt.ylabel('Inertia')plt.title('Elbow Method for Optimal k')plt.grid(True)plt.show()
1
# 엘보우기법 상 클러스터수는 3개 혹은 4개가 최적으로 보인다
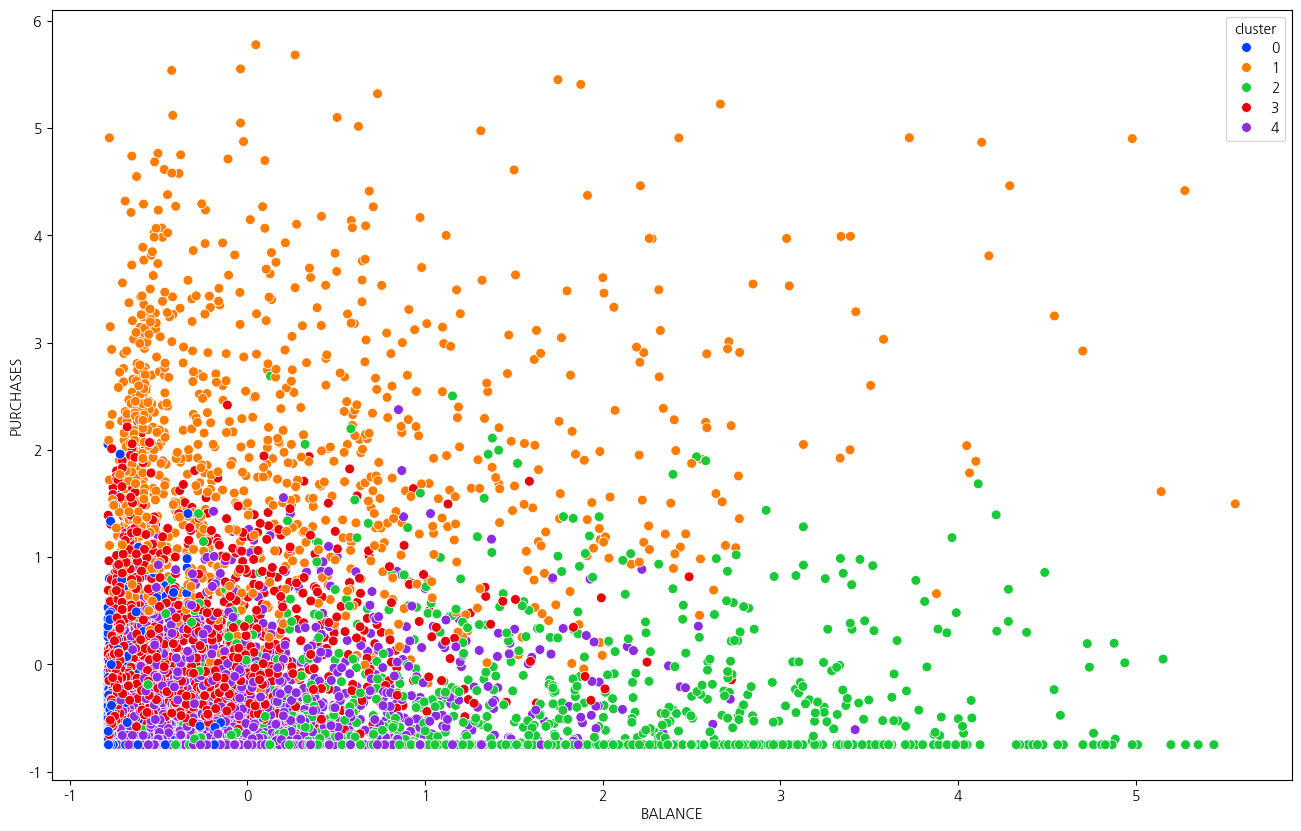
문제13 : 결과를 해석해보세요.
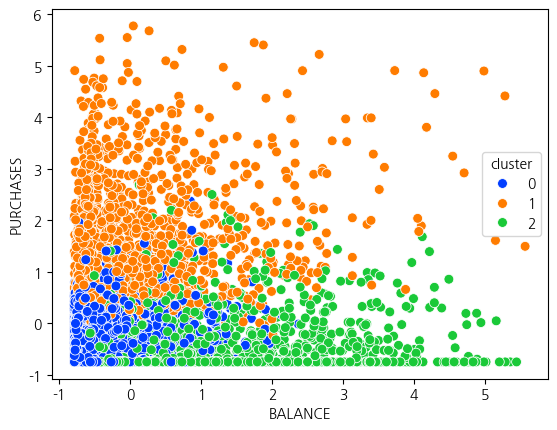
아래는 클러스터의 수를 5로 진행하고, 2가지 변수(BALANCE, PURCHASES)로 시각화를 한 결과입니다.
결과를 보고 추가 분석을 진행하여 인사이트를 발견해보세요. 클러스터 별로 어떤 차이가 있나요?
1
2
3
4
5
6
7
8
9
10
11
12
data11=scaled_df.copy()model=KMeans(n_clusters=5,random_state=21)model.fit(data11)data11['cluster']=model.predict(data11)# 군집별 데이터 개수 확인
cluster_counts2=data11['cluster'].value_counts()cluster_counts2# 시각화
plt.figure(figsize=(16,10))sns.scatterplot(x=data11['BALANCE'],y=data11['PURCHASES'],hue=data11['cluster'],s=50,palette='bright')
클러스터0 : 가장 낮은 잔액과 비교적 낮은 구매액을 가진 고객. 현금서비스이용도 거의 사용안하고있음. 총 지불액이 가장 낮게 나타남.
클러스터1 : 중간 정도의 잔액과 가장 높은 구매액 및 구매빈도를 가진 고객. 할부로 이루어진 구매액이 높고 총 지불액도 가장 높게 나타나고있음.
클러스터2 : 가장 높은 잔액과 비교적 낮은 구매액, 현금서비스를 가장 많이 이용한 고객. 총 지불액도 비교적 높게 나타나고있음. 최소 지불액이 가장 높고 다른 군집보다 확연하게 높음.
클러스터3 : 비교적 낮은 잔액과 비교적 높은 구매액 및 높은 구매빈도를 가진 고객. 할부 구매 빈도가 가장 높게 나타나고있음. 현금서비스 이용을 가장 낮게 사용하고있음.
클러스터4 : 중간 정도의 잔액과 구매빈도가 가장 낮은 고객. 할부 구매 빈도는 가장 낮게 나타남. 총 지불액이 비교적 낮게 나타남.
클러스터1은 구매빈도가 높은 충성고객으로 이들이 이탈하지않을만한 꾸준한 서비스를 제공할 필요가 있음
클러스터2는 다른 클러스터 집단보다 잔액이 압도적으로 많이 보유하고있는 고객들임. 다만, 현금서비스 이용도 높고 최소지불액도 높은것에비해 구매이용률이 낮아 구매를 유도할만한 상품이나 서비스가 필요함
클러스터0,3,4는 잔액과 구매빈도가 낮은편이다. 이들이 구매활동을 하기위한 적절한 서비스가 필요하다
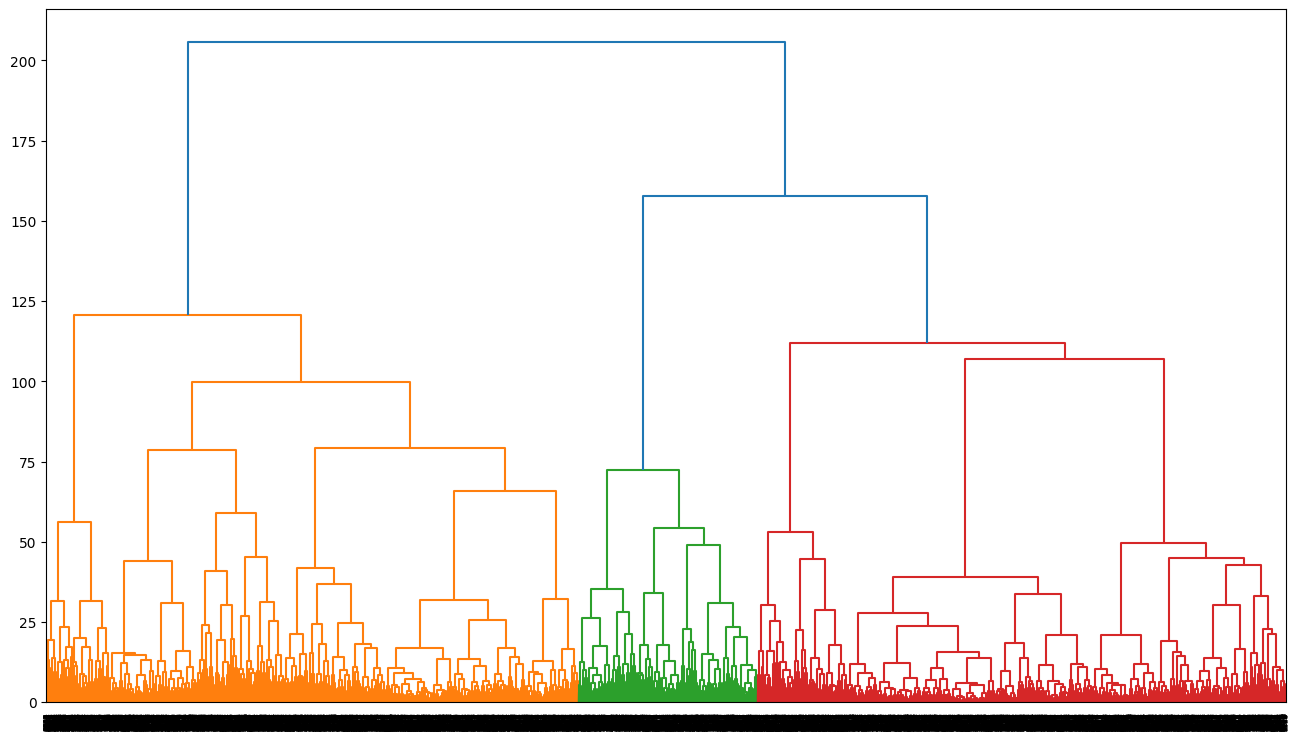
문제14: 계층적 클러스터링 모델 학습 및 덴드로그램 시각화
계층적 클러스터링을 scipy를 사용하여 모델을 학습하고, 덴드로그램을 시각화하세요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
fromscipy.cluster.hierarchyimportdendrogram,linkage,cut_treeimportmatplotlib.pyplotaspltdata12=scaled_df.copy()# 거리 : ward method 사용
model=linkage(data12,'ward')# single, complete, average, centroid, median 등
labelList=data12.index# 덴드로그램 사이즈와 스타일 조정
plt.figure(figsize=(16,9))plt.style.use("default")dendrogram(model,labels=labelList)plt.show()
1
2
3
4
5
6
7
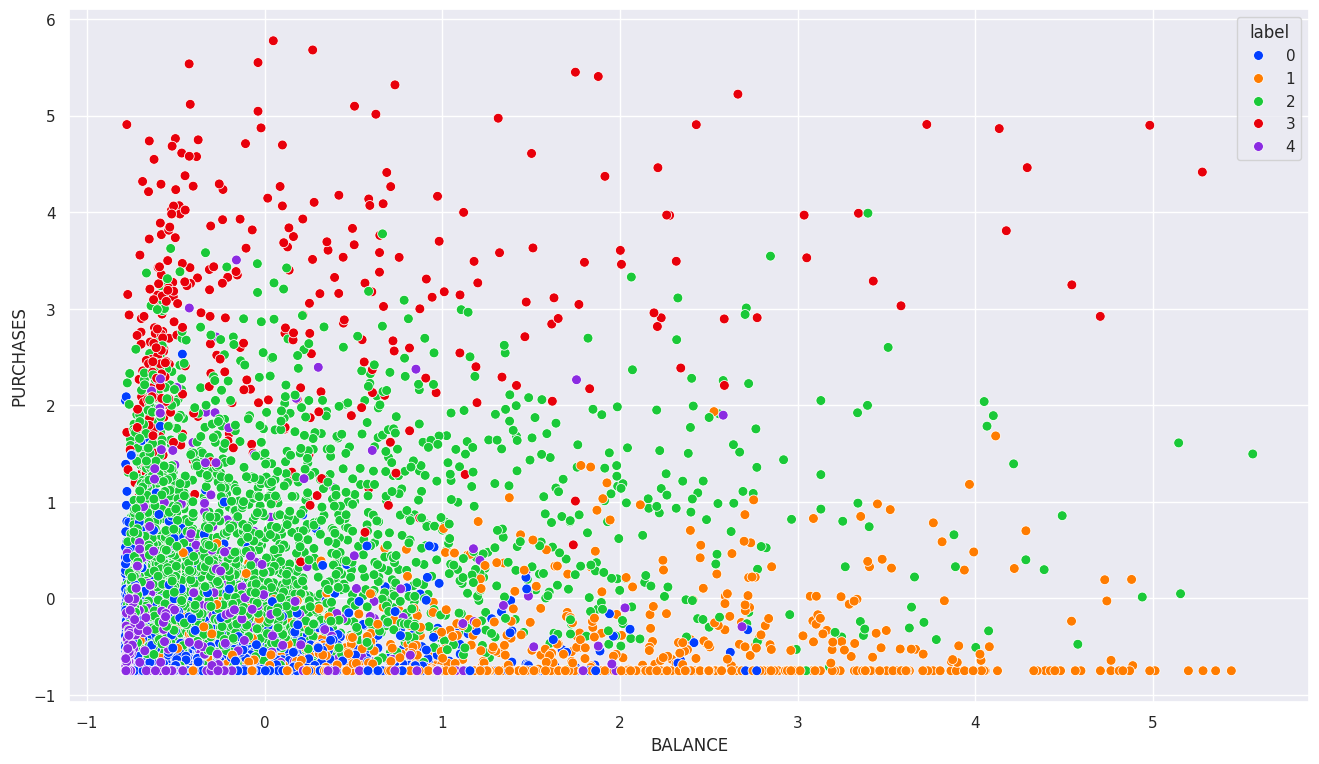
cluster_num=5# 고객별 클러스터 라벨 구하기
data12['label']=cut_tree(model,cluster_num)pd.DataFrame(data12['label'].value_counts())
importpandasaspdfromsklearn.clusterimportDBSCANimportmatplotlib.pyplotaspltimportseabornassnsdata13=scaled_df.copy()# DBSCAN 모델 생성
# eps와 min_samples는 데이터에 따라 조정해야 합니다.
dbscan=DBSCAN(eps=0.5,min_samples=5)# DBSCAN을 사용하여 클러스터링 수행
clusters=dbscan.fit_predict(data13)# 클러스터 레이블을 데이터프레임에 추가
data13['cluster']=clusters# 클러스터 개수 확인
cluster_counts=data13['cluster'].value_counts()print("Cluster Counts:")print(cluster_counts)
DBSCAN의 eps와 min_samples 값을 조정하여, 클러스터링 결과가 개선되도록 하세요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# DBSCAN 모델 학습 (매개변수 조정)
data14=scaled_df.copy()# DBSCAN 모델 생성
# eps와 min_samples는 데이터에 따라 조정해야 합니다.
dbscan=DBSCAN(eps=0.8,min_samples=5)# DBSCAN을 사용하여 클러스터링 수행
clusters=dbscan.fit_predict(data14)# 클러스터 레이블을 데이터프레임에 추가
data14['cluster']=clusters# 클러스터 개수 확인
cluster_counts=data14['cluster'].value_counts()print("Cluster Counts:")print(cluster_counts)
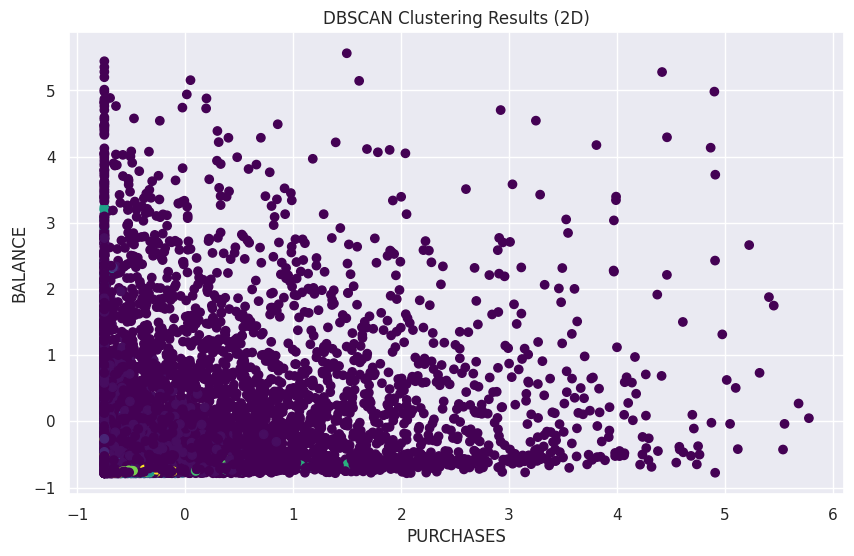
# DBSCAN 결과 시각화 (최적 매개변수 사용 후)
plt.figure(figsize=(10,6))plt.scatter(data14['PURCHASES'],data14['BALANCE'],c=data14['cluster'],cmap='viridis')plt.xlabel('PURCHASES')plt.ylabel('BALANCE')plt.title('DBSCAN Clustering Results (2D)')plt.show()
1
2
3
4
# 노이즈 데이터 개수 확인
noise_check=data14[data14['cluster']==-1]print(f"Number of noise points: {len(noise_check)}")
1
Number of noise points: 4891
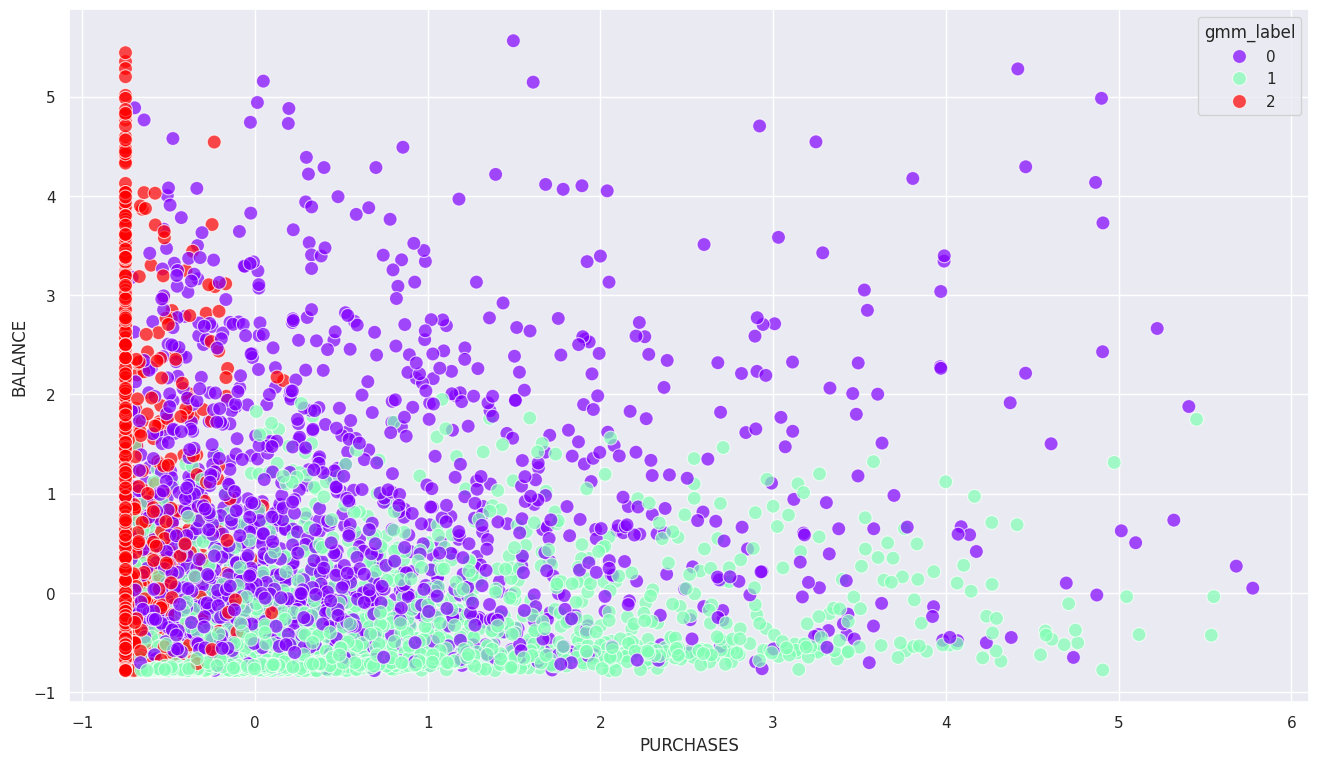
문제18: GMM 클러스터링 모델 학습
Gaussian Mixture Model을 사용하여 클러스터링 모델을 학습하고, 결과를 얻으세요. 클러스터의 수는 3으로 설정하세요.
1
2
3
4
5
6
7
8
9
10
fromsklearn.mixtureimportGaussianMixturedata15=scaled_df.copy()n_components=3random_state=21model=GaussianMixture(n_components=n_components,random_state=random_state)# GMM 모델 학습
model.fit(data15)data15['gmm_label']=model.predict(data15)print(data15['gmm_label'].value_counts())
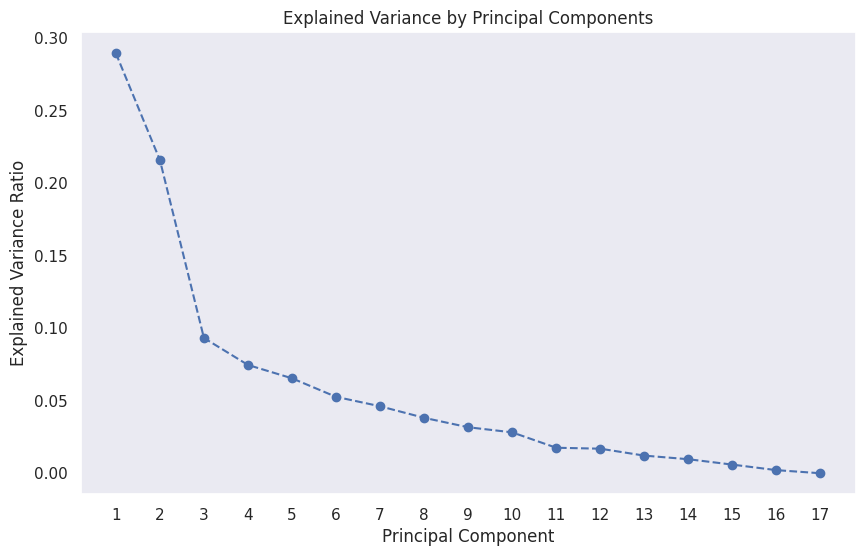
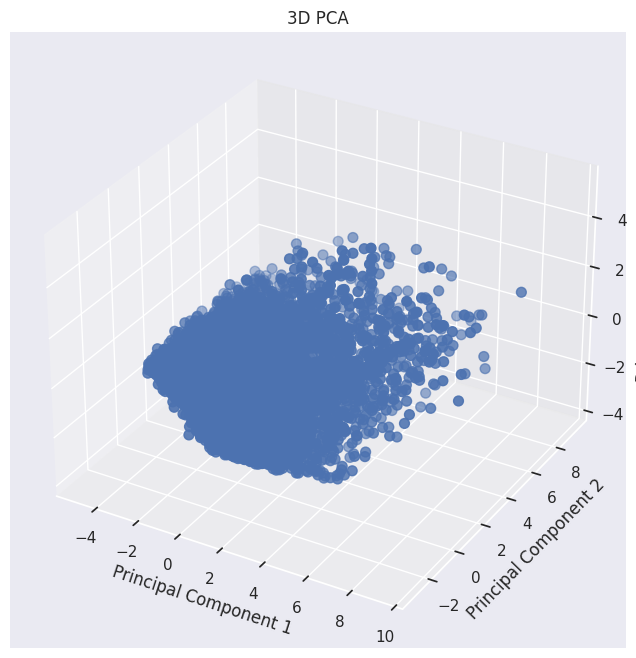
# 문제 22번을 통해 완만하게 바뀌는 지점인 주성분 3차원 기준으로 데이터 변환 진행
# 만약, 적정한 설명력을 가진 차원 축소를 하고싶다면 70% 이상인 5-7개의 주성분을 선택해야 함
data23=scaled_df.copy()pca=PCA(n_components=3)principal_components=pca.fit_transform(data23)pca_df=pd.DataFrame(data=principal_components,columns=['PC1','PC2','PC3'])fig=plt.figure(figsize=(12,8))ax=fig.add_subplot(111,projection='3d')ax.scatter(pca_df['PC1'],pca_df['PC2'],pca_df['PC3'],s=50)ax.set_title('3D PCA')ax.set_xlabel('Principal Component 1')ax.set_ylabel('Principal Component 2')ax.set_zlabel('Principal Component 3')plt.show()
PCA를 활용한 클러스터링 (6문제)
CUST_ID를 제외하면 분석 중인 데이터에 총 17개의 열이 있습니다. 차원이 너무 많아서 데이터의 분포나 특징을 시각화로 파악하는 것이 어렵네요. 관련하여, PCA를 통해 모든 차원의 특징을 최대한 살리면서, 동시에 데이터의 특징을 한눈에 파악할 수 있도록 2차원으로 차원을 축소해 봅시다.
문제24: PCA를 활용한 차원 축소 후 K-means 클러스터링
PCA를 통해 차원 축소한 데이터를 사용하여 K-means 클러스터링을 수행하고 결과를 분석해보세요.
# PCA 2차원 축소
data24=scaled_df.copy()data24.reset_index(drop=True,inplace=True)pca=PCA(n_components=2)pca_transformed=pca.fit_transform(data24)pca_df=pd.DataFrame(data=pca_transformed,columns=['PC1','PC2'])# 차원 축소한 데이터를 K-means 클러스터링 수행
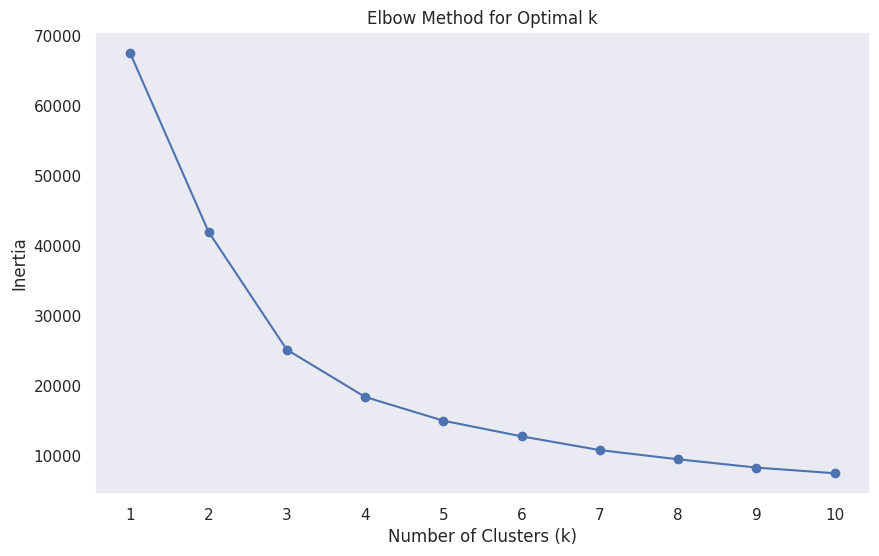
# 엘보우 기법 이용 최적의 군집 개수 확인
inertia=[]# 클러스터 수를 1에서 10까지 변화시키며 K-Means 수행
forkinrange(1,11):kmeans=KMeans(n_clusters=k,random_state=42)kmeans.fit(pca_df)inertia.append(kmeans.inertia_)# Elbow plot 시각화
plt.figure(figsize=(10,6))plt.plot(range(1,11),inertia,marker='o')plt.title('Elbow Method for Optimal k')plt.xlabel('Number of Clusters (k)')plt.ylabel('Inertia')plt.xticks(range(1,11))plt.grid()plt.show()
1
2
3
4
5
# 엘보우기법 시각화결과 군집개수 3개 기준으로 클러스터링 수행
optimal_k=3kmeans=KMeans(n_clusters=optimal_k,random_state=21)pca_df['cluster']=kmeans.fit_predict(pca_df)pca_df
PC1
PC2
cluster
0
-1.272749
-2.012017
0
1
-2.693997
3.122103
1
2
1.308761
0.557358
2
3
-0.377331
-0.426854
0
4
-1.411984
-1.458604
0
...
...
...
...
7855
0.766955
-2.521954
0
7856
-1.045427
-1.483733
0
7857
-1.247922
-1.783102
0
7858
0.060160
-2.381176
0
7859
-1.056373
0.633281
0
7860 rows × 3 columns
1
2
3
4
# 클러스터 개수 확인
cluster_counts=pca_df['cluster'].value_counts()print("Cluster Counts:")print(cluster_counts)
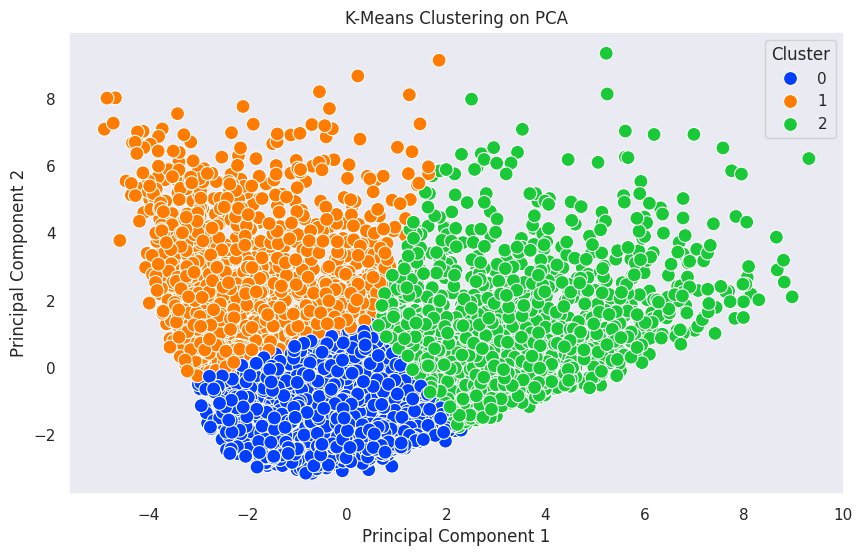
# 클러스터링 결과 시각화
plt.figure(figsize=(10,6))sns.scatterplot(x='PC1',y='PC2',hue='cluster',data=pca_df,palette='bright',s=100)plt.title('K-Means Clustering on PCA')plt.xlabel('Principal Component 1')plt.ylabel('Principal Component 2')plt.legend(title='Cluster')plt.grid()plt.show()
1
2
3
4
5
6
7
# PCA 모델 학습
pca=PCA(n_components=2)pca.fit(data24)# 주성분 로딩 값 확인
loadings=pd.DataFrame(pca.components_.T,columns=['PC1','PC2'],index=data24.columns)print(loadings)
# 클러스터별 고객 특성 파악하기
mask1=data24.groupby('cluster').mean()mask1['cluster_counts']=data24['cluster'].value_counts()mask1.T
cluster
0
1
2
BALANCE
-0.423397
1.109025
0.006890
BALANCE_FREQUENCY
-0.297038
0.366001
0.400171
PURCHASES
-0.379753
-0.477710
1.418891
ONEOFF_PURCHASES
-0.314337
-0.320109
1.102216
INSTALLMENTS_PURCHASES
-0.279808
-0.461005
1.150061
CASH_ADVANCE
-0.373524
1.327753
-0.329119
PURCHASES_FREQUENCY
-0.158581
-0.708416
1.080807
ONEOFF_PURCHASES_FREQUENCY
-0.300788
-0.329786
1.077230
PURCHASES_INSTALLMENTS_FREQUENCY
-0.107056
-0.613825
0.859723
CASH_ADVANCE_FREQUENCY
-0.367145
1.359571
-0.375781
CASH_ADVANCE_TRX
-0.368886
1.332030
-0.344954
PURCHASES_TRX
-0.338236
-0.513253
1.347979
CREDIT_LIMIT
-0.347275
0.400359
0.494277
PAYMENTS
-0.404550
0.453219
0.588431
MINIMUM_PAYMENTS
-0.360473
0.878280
0.069117
PRC_FULL_PAYMENT
0.006958
-0.429023
0.394028
TENURE
-0.065700
-0.060773
0.224490
cluster_counts
4429.000000
1680.000000
1751.000000
클러스터별 고객 특성
클러스터 0 : 잔액이 가장 적은 고객. 총구매액과 구매빈도가 비교적 낮은 고객. 현금서비스 이용이 낮은 고객. 신용한도는 비교적 낮은 고객. 총 지불액이 가장 낮고 최소 지불액도 가장낮은 고객.
클러스터 1 : 잔액을 가장 많이 보유한 고객. 총구매액과 구매빈도가 가장 낮은 고객. 현금서비스 인출 금액과 빈도, 거래 횟수가 가장 높은 고객. 신용 한도는 비교적 높은 고객. 총 지불액은 비교적 높고 최소 지불액이 가장 높은 고객.
클러스터 2 : 평균적인 잔액 보유 고객. 총구매액과 구매빈도가 가장 높은 고객. 현금서비스 이용이 낮은 고객. 신용한도는 가장 높은 고객. 총 지불액이 가장 높고 최소 지불액은 평균인 고객.
군집별 대출서비스 제안
클러스터 0 : 잔액이 낮아 현금서비스 이용을 유도해야한다. 소액대출 서비스나 장기대출 서비스 혹은 낮은 이자율로 단기대출 서비스 등을 제공하여 현금을 마련할수있도록 유도하고 구매를 촉진
클러스터 1 : 잔액과 현금서비스 이용도 높고 구매빈도는 낮지만 최소지불액은 높은것으로보아 고가형 상품을 구매하는 고객으로 판단된다. 이들이 고가형 상품을 구매할수있도록 흥미있는 상품들을 제시함과 동시에 고가상품 대상으로 잔액과 신용한도 등을 고려하여 합리적인 대출서비스를 제안하여 구매를 촉진한다.
클러스터 2 : 구매빈도에 따른 대출 이자율 할인 등으로 충성고객에 맞춤형 대출서비스를 제안한다. 이들은 현금서비스 이용률이 높지않아 소액대출 등의 금전적인 부담이 적은 대출을 제안할 필요가 있다
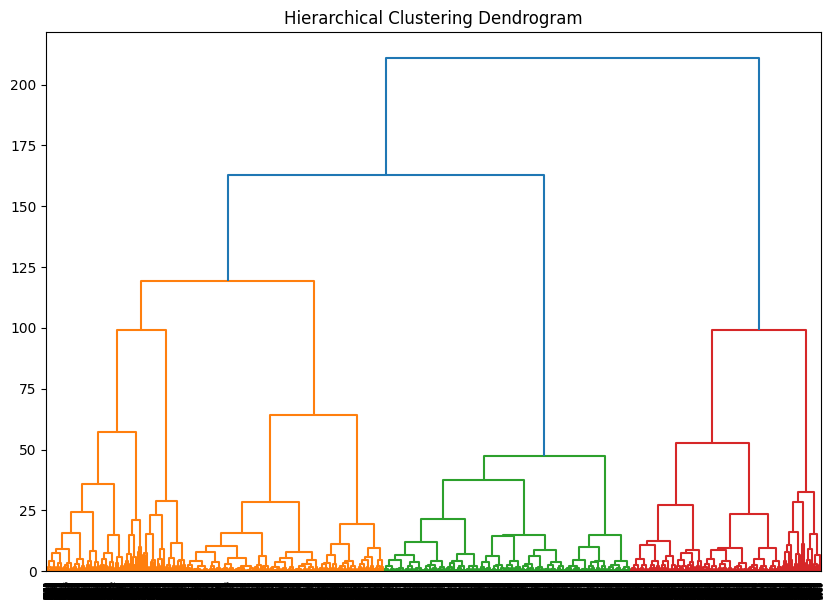
문제26 : PCA를 활용한 차원 축소 후 계층적 클러스터링
PCA를 통해 차원 축소한 데이터를 사용하여 계층적 클러스터링을 수행하고 덴드로그램을 시각화하세요.
1
2
3
4
5
6
7
8
9
10
11
fromscipy.cluster.hierarchyimportdendrogram,linkage,cut_treeimportmatplotlib.pyplotasplt# 거리 : ward method 사용
model=linkage(pca_transformed,'ward')# single, complete, average, centroid, median 등
# 덴드로그램 사이즈와 스타일 조정
plt.figure(figsize=(10,7))dendrogram(model,orientation='top',distance_sort='descending',show_leaf_counts=True)plt.title('Hierarchical Clustering Dendrogram')plt.show()
문제27 : PCA를 활용한 차원 축소 후 DBSCAN 클러스터링
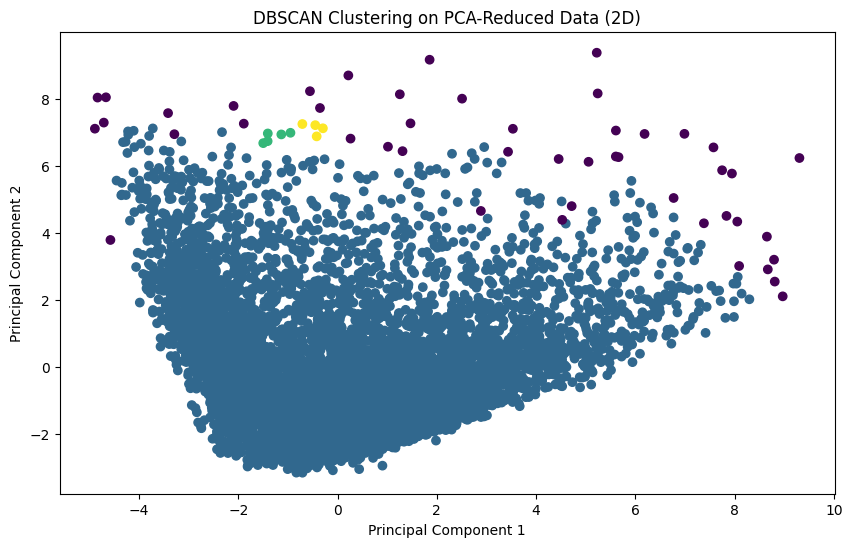
PCA를 통해 차원 축소한 데이터를 사용하여 DBSCAN 클러스터링을 수행하고 결과를 시각화하세요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
fromsklearn.clusterimportDBSCAN# DBSCAN 모델 학습
dbscan_pca=DBSCAN(eps=0.5,min_samples=5)dbscan_pca.fit(pca_transformed)# 클러스터 할당 결과
pca_df_dbscan=pd.DataFrame(data=pca_transformed,columns=['PC1','PC2'])pca_df_dbscan['Cluster']=dbscan_pca.labels_# 클러스터링 결과 시각화
plt.figure(figsize=(10,6))plt.scatter(pca_df_dbscan['PC1'],pca_df_dbscan['PC2'],c=pca_df_dbscan['Cluster'],cmap='viridis')plt.xlabel('Principal Component 1')plt.ylabel('Principal Component 2')plt.title('DBSCAN Clustering on PCA-Reduced Data (2D)')plt.show()
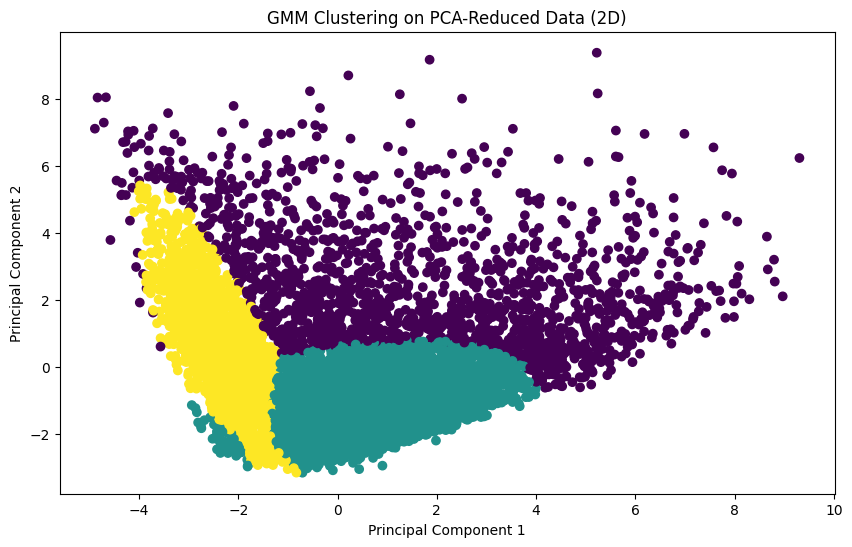
문제28 : PCA를 활용한 차원 축소 후 GMM 클러스터링
PCA를 통해 차원 축소한 데이터를 사용하여 GMM 클러스터링을 수행하고 결과를 시각화하세요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
fromsklearn.mixtureimportGaussianMixture# GMM 모델 학습
gmm_pca=GaussianMixture(n_components=3,random_state=42)gmm_pca.fit(pca_transformed)# 클러스터 할당 결과
pca_df_gmm=pd.DataFrame(data=pca_transformed,columns=['PC1','PC2'])pca_df_gmm['Cluster']=gmm_pca.predict(pca_transformed)# 클러스터링 결과 시각화
plt.figure(figsize=(10,6))plt.scatter(pca_df_gmm['PC1'],pca_df_gmm['PC2'],c=pca_df_gmm['Cluster'],cmap='viridis')plt.xlabel('Principal Component 1')plt.ylabel('Principal Component 2')plt.title('GMM Clustering on PCA-Reduced Data (2D)')plt.show()
문제29 : 원본 데이터와 차원 축소 데이터를 사용한 클러스터링 결과 비교
원본 데이터와 차원 축소 데이터를 사용하여 다양한 클러스터링 기법을 적용한 결과를 비교해보세요.