파이썬 데이터분석 데이터시각화 실습
- 고객의 정기예금 가입 여부 예측을 위한 은행 마케팅 분류 모델 구축
- 자전거 대여 수요 예측을 위한 머신러닝 모델 구축
- 파이썬 데이터분석 - A/B test 분석
- 파이썬 데이터분석 - aarrr 분석 실습
- 파이썬 데이터분석 - 장바구니 분석(연관분석)2 - FP-Growth, 순차패턴마이닝
- 파이썬 데이터분석 - 장바구니 분석(연관분석) 실습
- 파이썬 데이터분석 - 장바구니 분석(연관분석)
- 파이썬 데이터분석 데이터시각화2
- 파이썬 데이터분석 데이터시각화1
- 파이썬 데이터분석 클러스터와 차원축소 실습
- 파이썬 데이터분석 클러스터와 차원축소2
- 파이썬 데이터분석 클러스터와 차원축소
- 파이썬 데이터분석 라이브러리
1
2
3
4
5
6
### 개발환경 세팅하기
# ▶ 한글 폰트 다운로드
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
fonts-nanum is already the newest version (20200506-1).
0 upgraded, 0 newly installed, 0 to remove and 49 not upgraded.
/usr/share/fonts: caching, new cache contents: 0 fonts, 1 dirs
/usr/share/fonts/truetype: caching, new cache contents: 0 fonts, 3 dirs
/usr/share/fonts/truetype/humor-sans: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/liberation: caching, new cache contents: 16 fonts, 0 dirs
/usr/share/fonts/truetype/nanum: caching, new cache contents: 12 fonts, 0 dirs
/usr/local/share/fonts: caching, new cache contents: 0 fonts, 0 dirs
/root/.local/share/fonts: skipping, no such directory
/root/.fonts: skipping, no such directory
/usr/share/fonts/truetype: skipping, looped directory detected
/usr/share/fonts/truetype/humor-sans: skipping, looped directory detected
/usr/share/fonts/truetype/liberation: skipping, looped directory detected
/usr/share/fonts/truetype/nanum: skipping, looped directory detected
/var/cache/fontconfig: cleaning cache directory
/root/.cache/fontconfig: not cleaning non-existent cache directory
/root/.fontconfig: not cleaning non-existent cache directory
fc-cache: succeeded
1
2
3
4
5
6
7
8
9
10
11
12
# ▶ 한글 폰트 설정하기
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
plt.rcParams['axes.unicode_minus'] =False
# ▶ Warnings 제거
import warnings
warnings.filterwarnings('ignore')
# ▶ Google drive mount or 폴더 클릭 후 구글드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
1
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
##########################################
### 한글이 깨지는 경우 아래 코드 실행하기 !!!###
##########################################
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 나눔고딕 폰트를 설치합니다.
!apt-get install -y fonts-nanum
!fc-cache -fv
# 설치된 나눔고딕 폰트를 matplotlib에 등록합니다.
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf'
fm.fontManager.addfont(font_path)
plt.rcParams['font.family'] = 'NanumGothic'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
fonts-nanum is already the newest version (20200506-1).
0 upgraded, 0 newly installed, 0 to remove and 49 not upgraded.
/usr/share/fonts: caching, new cache contents: 0 fonts, 1 dirs
/usr/share/fonts/truetype: caching, new cache contents: 0 fonts, 3 dirs
/usr/share/fonts/truetype/humor-sans: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/liberation: caching, new cache contents: 16 fonts, 0 dirs
/usr/share/fonts/truetype/nanum: caching, new cache contents: 12 fonts, 0 dirs
/usr/local/share/fonts: caching, new cache contents: 0 fonts, 0 dirs
/root/.local/share/fonts: skipping, no such directory
/root/.fonts: skipping, no such directory
/usr/share/fonts/truetype: skipping, looped directory detected
/usr/share/fonts/truetype/humor-sans: skipping, looped directory detected
/usr/share/fonts/truetype/liberation: skipping, looped directory detected
/usr/share/fonts/truetype/nanum: skipping, looped directory detected
/var/cache/fontconfig: cleaning cache directory
/root/.cache/fontconfig: not cleaning non-existent cache directory
/root/.fontconfig: not cleaning non-existent cache directory
fc-cache: succeeded
1
2
3
4
import os
import pandas as pd
import numpy as np
import seaborn as sns
분석주제 : 회사의 매출 개선을 위한 고객의 구매 패턴 분석
- 고객의 사용 패턴을 분석하여 고객을 그룹화하고, 각 그룹에 맞는 마케팅 전략 수립
- 수립된 마케팅 전략을 통해 회사의 매출 증대 및 고객 만족도 제고
데이터 준비하기
데이터 준비하기
데이터 출처: Kaggle
Credit Card Dataset데이터 명세
| No. | 표준항목명 | 영문명 | 설명 | 표현형식/단위 | 예시 |
|---|---|---|---|---|---|
| 1 | 고객 ID | CUST_ID | 고객을 식별하기 위한 고유 ID | - | C10001 |
| 2 | 잔액 | BALANCE | 신용카드 계좌의 현재 잔액 | N | 40.9 |
| 3 | 잔액 업데이트 빈도 | BALANCE_FREQUENCY | 잔액이 업데이트 되는 빈도 | N | 0.818 |
| 4 | 총 구매액 | PURCHASES | 신용카드로 이루어진 총 구매액 | N | 95.4 |
| 5 | 일회성 구매액 | ONEOFF_PURCHASES | 일회성으로 이루어진 구매액 | N | 0.0 |
| 6 | 할부 구매액 | INSTALLMENTS_PURCHASES | 할부로 이루어진 구매액 | N | 95.4 |
| 7 | 현금 서비스 금액 | CASH_ADVANCE | 현금 서비스로 인출한 금액 | N | 0.0 |
| 8 | 구매 빈도 | PURCHASES_FREQUENCY | 구매가 이루어진 빈도 | N | 0.167 |
| 9 | 일회성 구매 빈도 | ONEOFF_PURCHASES_FREQUENCY | 일회성 구매가 이루어진 빈도 | N | 0.0 |
| 10 | 할부 구매 빈도 | PURCHASES_INSTALLMENTS_FREQUENCY | 할부 구매가 이루어진 빈도 | N | 0.083 |
| 11 | 현금 서비스 빈도 | CASH_ADVANCE_FREQUENCY | 현금 서비스가 이루어진 빈도 | N | 0.0 |
| 12 | 현금 서비스 거래 횟수 | CASH_ADVANCE_TRX | 현금 서비스 거래의 횟수 | N | 0 |
| 13 | 구매 횟수 | PURCHASES_TRX | 총 구매 거래의 횟수 | N | 2 |
| 14 | 신용 한도 | CREDIT_LIMIT | 신용카드의 신용 한도 | N | 1000.0 |
| 15 | 지불액 | PAYMENTS | 신용카드 계좌에 지불한 총 금액 | N | 201.8 |
| 16 | 최소 지불액 | MINIMUM_PAYMENTS | 신용카드 계좌의 최소 지불액 | N | 139.5 |
| 17 | 전액 지불 비율 | PRC_FULL_PAYMENT | 신용카드 결제 금액 중 전액을 지불한 비율 | N | 0.0 |
| 18 | 카드 소지 기간 | TENURE | 신용카드 계좌를 소지한 기간 (월) | N | 12 |
데이터 전처리
1
2
3
# 데이터 불러오기
data = pd.read_csv("/content/drive/MyDrive/CC GENERAL.csv")
data
| CUST_ID | BALANCE | BALANCE_FREQUENCY | PURCHASES | ONEOFF_PURCHASES | INSTALLMENTS_PURCHASES | CASH_ADVANCE | PURCHASES_FREQUENCY | ONEOFF_PURCHASES_FREQUENCY | PURCHASES_INSTALLMENTS_FREQUENCY | CASH_ADVANCE_FREQUENCY | CASH_ADVANCE_TRX | PURCHASES_TRX | CREDIT_LIMIT | PAYMENTS | MINIMUM_PAYMENTS | PRC_FULL_PAYMENT | TENURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | C10001 | 40.900749 | 0.818182 | 95.40 | 0.00 | 95.40 | 0.000000 | 0.166667 | 0.000000 | 0.083333 | 0.000000 | 0 | 2 | 1000.0 | 201.802084 | 139.509787 | 0.000000 | 12 |
| 1 | C10002 | 3202.467416 | 0.909091 | 0.00 | 0.00 | 0.00 | 6442.945483 | 0.000000 | 0.000000 | 0.000000 | 0.250000 | 4 | 0 | 7000.0 | 4103.032597 | 1072.340217 | 0.222222 | 12 |
| 2 | C10003 | 2495.148862 | 1.000000 | 773.17 | 773.17 | 0.00 | 0.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0 | 12 | 7500.0 | 622.066742 | 627.284787 | 0.000000 | 12 |
| 3 | C10004 | 1666.670542 | 0.636364 | 1499.00 | 1499.00 | 0.00 | 205.788017 | 0.083333 | 0.083333 | 0.000000 | 0.083333 | 1 | 1 | 7500.0 | 0.000000 | NaN | 0.000000 | 12 |
| 4 | C10005 | 817.714335 | 1.000000 | 16.00 | 16.00 | 0.00 | 0.000000 | 0.083333 | 0.083333 | 0.000000 | 0.000000 | 0 | 1 | 1200.0 | 678.334763 | 244.791237 | 0.000000 | 12 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 8945 | C19186 | 28.493517 | 1.000000 | 291.12 | 0.00 | 291.12 | 0.000000 | 1.000000 | 0.000000 | 0.833333 | 0.000000 | 0 | 6 | 1000.0 | 325.594462 | 48.886365 | 0.500000 | 6 |
| 8946 | C19187 | 19.183215 | 1.000000 | 300.00 | 0.00 | 300.00 | 0.000000 | 1.000000 | 0.000000 | 0.833333 | 0.000000 | 0 | 6 | 1000.0 | 275.861322 | NaN | 0.000000 | 6 |
| 8947 | C19188 | 23.398673 | 0.833333 | 144.40 | 0.00 | 144.40 | 0.000000 | 0.833333 | 0.000000 | 0.666667 | 0.000000 | 0 | 5 | 1000.0 | 81.270775 | 82.418369 | 0.250000 | 6 |
| 8948 | C19189 | 13.457564 | 0.833333 | 0.00 | 0.00 | 0.00 | 36.558778 | 0.000000 | 0.000000 | 0.000000 | 0.166667 | 2 | 0 | 500.0 | 52.549959 | 55.755628 | 0.250000 | 6 |
| 8949 | C19190 | 372.708075 | 0.666667 | 1093.25 | 1093.25 | 0.00 | 127.040008 | 0.666667 | 0.666667 | 0.000000 | 0.333333 | 2 | 23 | 1200.0 | 63.165404 | 88.288956 | 0.000000 | 6 |
8950 rows × 18 columns
1
2
# 데이터프레임의 기본 정보 확인
data.info()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8950 entries, 0 to 8949
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CUST_ID 8950 non-null object
1 BALANCE 8950 non-null float64
2 BALANCE_FREQUENCY 8950 non-null float64
3 PURCHASES 8950 non-null float64
4 ONEOFF_PURCHASES 8950 non-null float64
5 INSTALLMENTS_PURCHASES 8950 non-null float64
6 CASH_ADVANCE 8950 non-null float64
7 PURCHASES_FREQUENCY 8950 non-null float64
8 ONEOFF_PURCHASES_FREQUENCY 8950 non-null float64
9 PURCHASES_INSTALLMENTS_FREQUENCY 8950 non-null float64
10 CASH_ADVANCE_FREQUENCY 8950 non-null float64
11 CASH_ADVANCE_TRX 8950 non-null int64
12 PURCHASES_TRX 8950 non-null int64
13 CREDIT_LIMIT 8949 non-null float64
14 PAYMENTS 8950 non-null float64
15 MINIMUM_PAYMENTS 8637 non-null float64
16 PRC_FULL_PAYMENT 8950 non-null float64
17 TENURE 8950 non-null int64
dtypes: float64(14), int64(3), object(1)
memory usage: 1.2+ MB
1
2
# 각 변수의 기술 통계량 확인
data.describe()
| BALANCE | BALANCE_FREQUENCY | PURCHASES | ONEOFF_PURCHASES | INSTALLMENTS_PURCHASES | CASH_ADVANCE | PURCHASES_FREQUENCY | ONEOFF_PURCHASES_FREQUENCY | PURCHASES_INSTALLMENTS_FREQUENCY | CASH_ADVANCE_FREQUENCY | CASH_ADVANCE_TRX | PURCHASES_TRX | CREDIT_LIMIT | PAYMENTS | MINIMUM_PAYMENTS | PRC_FULL_PAYMENT | TENURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 8950.000000 | 8950.000000 | 8950.000000 | 8950.000000 | 8950.000000 | 8950.000000 | 8950.000000 | 8950.000000 | 8950.000000 | 8950.000000 | 8950.000000 | 8950.000000 | 8949.000000 | 8950.000000 | 8637.000000 | 8950.000000 | 8950.000000 |
| mean | 1564.474828 | 0.877271 | 1003.204834 | 592.437371 | 411.067645 | 978.871112 | 0.490351 | 0.202458 | 0.364437 | 0.135144 | 3.248827 | 14.709832 | 4494.449450 | 1733.143852 | 864.206542 | 0.153715 | 11.517318 |
| std | 2081.531879 | 0.236904 | 2136.634782 | 1659.887917 | 904.338115 | 2097.163877 | 0.401371 | 0.298336 | 0.397448 | 0.200121 | 6.824647 | 24.857649 | 3638.815725 | 2895.063757 | 2372.446607 | 0.292499 | 1.338331 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 50.000000 | 0.000000 | 0.019163 | 0.000000 | 6.000000 |
| 25% | 128.281915 | 0.888889 | 39.635000 | 0.000000 | 0.000000 | 0.000000 | 0.083333 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 1600.000000 | 383.276166 | 169.123707 | 0.000000 | 12.000000 |
| 50% | 873.385231 | 1.000000 | 361.280000 | 38.000000 | 89.000000 | 0.000000 | 0.500000 | 0.083333 | 0.166667 | 0.000000 | 0.000000 | 7.000000 | 3000.000000 | 856.901546 | 312.343947 | 0.000000 | 12.000000 |
| 75% | 2054.140036 | 1.000000 | 1110.130000 | 577.405000 | 468.637500 | 1113.821139 | 0.916667 | 0.300000 | 0.750000 | 0.222222 | 4.000000 | 17.000000 | 6500.000000 | 1901.134317 | 825.485459 | 0.142857 | 12.000000 |
| max | 19043.138560 | 1.000000 | 49039.570000 | 40761.250000 | 22500.000000 | 47137.211760 | 1.000000 | 1.000000 | 1.000000 | 1.500000 | 123.000000 | 358.000000 | 30000.000000 | 50721.483360 | 76406.207520 | 1.000000 | 12.000000 |
중복값 처리
1
2
# 중복값 확인
data.duplicated(keep=False).sum()
1
0
결측치 처리
1
2
3
data = data.drop(columns='CUST_ID')
data.isna().sum().sort_values(ascending=False)
# 최소 지불액 변수에서 313개 결측치, 신용 한도에서 1개 결측치 관찰됨
| 0 | |
|---|---|
| MINIMUM_PAYMENTS | 313 |
| CREDIT_LIMIT | 1 |
| BALANCE | 0 |
| CASH_ADVANCE_FREQUENCY | 0 |
| PRC_FULL_PAYMENT | 0 |
| PAYMENTS | 0 |
| PURCHASES_TRX | 0 |
| CASH_ADVANCE_TRX | 0 |
| PURCHASES_INSTALLMENTS_FREQUENCY | 0 |
| BALANCE_FREQUENCY | 0 |
| ONEOFF_PURCHASES_FREQUENCY | 0 |
| PURCHASES_FREQUENCY | 0 |
| CASH_ADVANCE | 0 |
| INSTALLMENTS_PURCHASES | 0 |
| ONEOFF_PURCHASES | 0 |
| PURCHASES | 0 |
| TENURE | 0 |
1
2
3
4
# 신용 한도 결측치 1개는 단순제거를 수행한다
data = data.dropna(subset=['CREDIT_LIMIT'])
data['MINIMUM_PAYMENTS'].describe()
| MINIMUM_PAYMENTS | |
|---|---|
| count | 8636.000000 |
| mean | 864.304943 |
| std | 2372.566350 |
| min | 0.019163 |
| 25% | 169.163545 |
| 50% | 312.452292 |
| 75% | 825.496463 |
| max | 76406.207520 |
1
2
3
4
# 최소 지불액 시각화 : 75%가 825인데 max값이 76406이다. 결측치는 중앙값처리가 더 적절해보인다.
sns.histplot(data['MINIMUM_PAYMENTS'])
plt.title("MINIMUM_PAYMENTS의 데이터 분포")
plt.show()
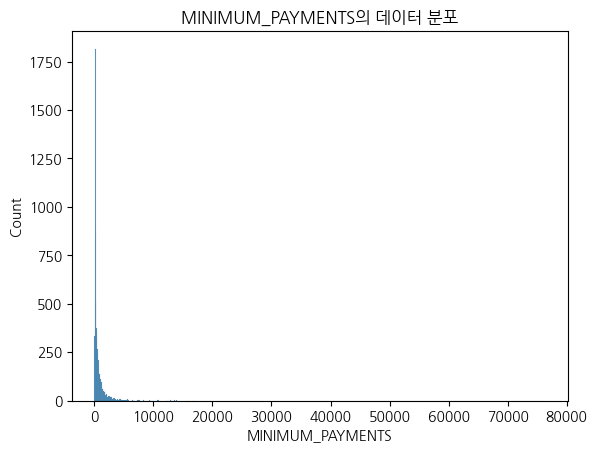
1
2
# 최소지불액과 지불액 관계 : 최소지불액 결측치가 지불액에서 어떻게 나타나는지 확인
data['PAYMENTS'][data['MINIMUM_PAYMENTS'].isna()].value_counts().sort_values(ascending=False)
| count | |
|---|---|
| PAYMENTS | |
| 0.000000 | 240 |
| 432.927281 | 1 |
| 746.691026 | 1 |
| 1159.135064 | 1 |
| 29272.486070 | 1 |
| ... | ... |
| 295.937124 | 1 |
| 3905.430817 | 1 |
| 5.070726 | 1 |
| 578.819329 | 1 |
| 275.861322 | 1 |
74 rows × 1 columns
1
2
3
4
5
6
7
8
9
10
11
12
13
# 최소지불액 결측치 처리
# 1) 지불액 변수값이 0이다 : 최소지불액 결측치도 0으로 처리
# 2) 지불액 변수값이 0이 아니다 : 최소지불액 결측치 중앙값 처리
median_minimum_payments = data['MINIMUM_PAYMENTS'].median()
for index, row in data.iterrows():
if pd.isnull(row['MINIMUM_PAYMENTS']):
if row['PAYMENTS'] == 0:
data.at[index, 'MINIMUM_PAYMENTS'] = 0
else:
data.at[index, 'MINIMUM_PAYMENTS'] = median_minimum_payments
data.isna().sum().sort_values(ascending=False)
| 0 | |
|---|---|
| BALANCE | 0 |
| CASH_ADVANCE_FREQUENCY | 0 |
| PRC_FULL_PAYMENT | 0 |
| MINIMUM_PAYMENTS | 0 |
| PAYMENTS | 0 |
| CREDIT_LIMIT | 0 |
| PURCHASES_TRX | 0 |
| CASH_ADVANCE_TRX | 0 |
| PURCHASES_INSTALLMENTS_FREQUENCY | 0 |
| BALANCE_FREQUENCY | 0 |
| ONEOFF_PURCHASES_FREQUENCY | 0 |
| PURCHASES_FREQUENCY | 0 |
| CASH_ADVANCE | 0 |
| INSTALLMENTS_PURCHASES | 0 |
| ONEOFF_PURCHASES | 0 |
| PURCHASES | 0 |
| TENURE | 0 |
이상치 처리
1
data.columns
1
2
3
4
5
6
7
Index(['BALANCE', 'BALANCE_FREQUENCY', 'PURCHASES', 'ONEOFF_PURCHASES',
'INSTALLMENTS_PURCHASES', 'CASH_ADVANCE', 'PURCHASES_FREQUENCY',
'ONEOFF_PURCHASES_FREQUENCY', 'PURCHASES_INSTALLMENTS_FREQUENCY',
'CASH_ADVANCE_FREQUENCY', 'CASH_ADVANCE_TRX', 'PURCHASES_TRX',
'CREDIT_LIMIT', 'PAYMENTS', 'MINIMUM_PAYMENTS', 'PRC_FULL_PAYMENT',
'TENURE'],
dtype='object')
1
2
3
4
5
6
7
8
9
10
11
# 이상치 제거 전 시각화
plt.figure(figsize=(20,16))
for index, col in enumerate(data):
plt.subplot(4, 5, index + 1)
sns.boxplot(data=data, y=col)
plt.title(f"{col} 데이터 분포")
plt.xlabel('')
plt.ylabel('')
plt.tight_layout()
plt.show()
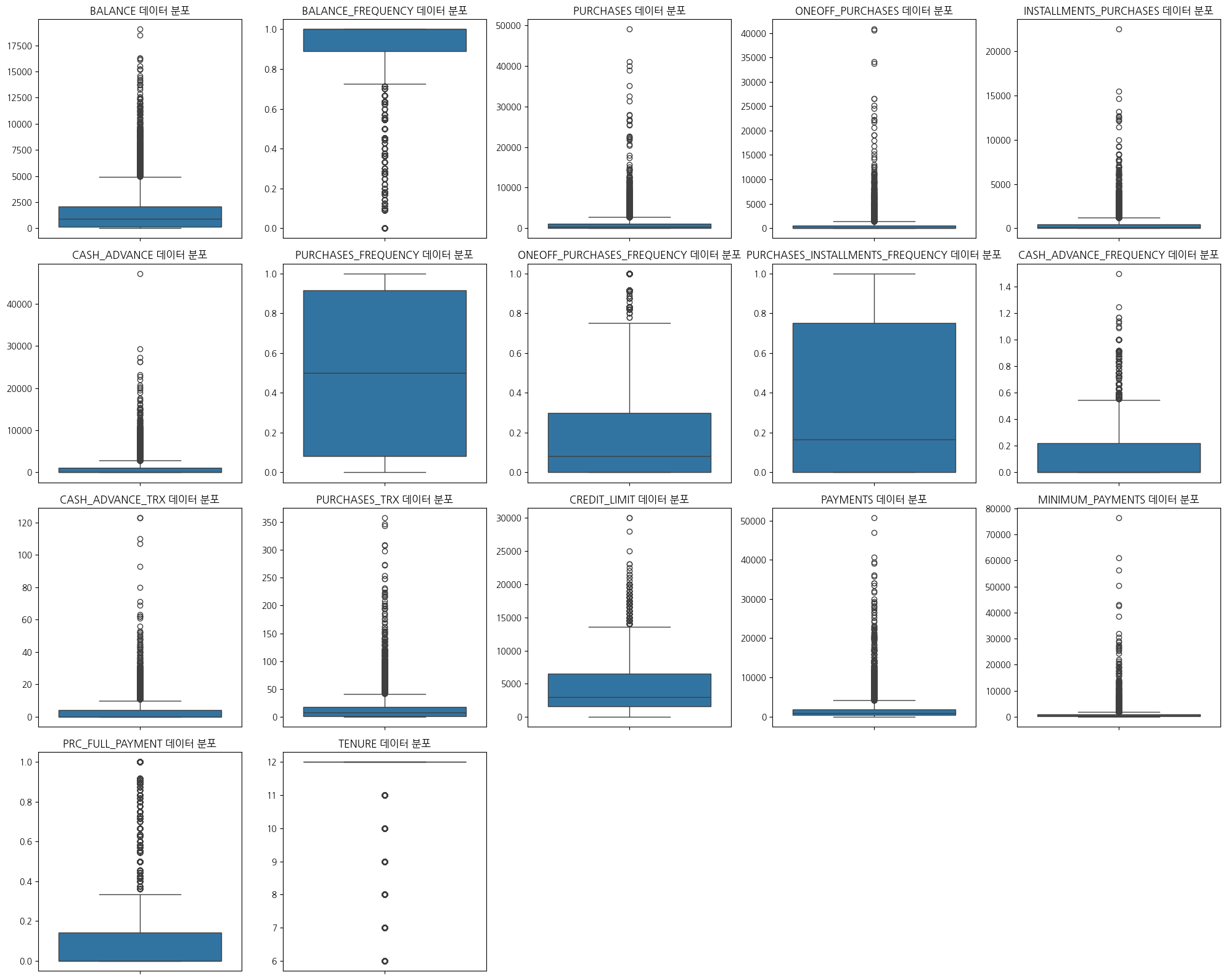
1
2
3
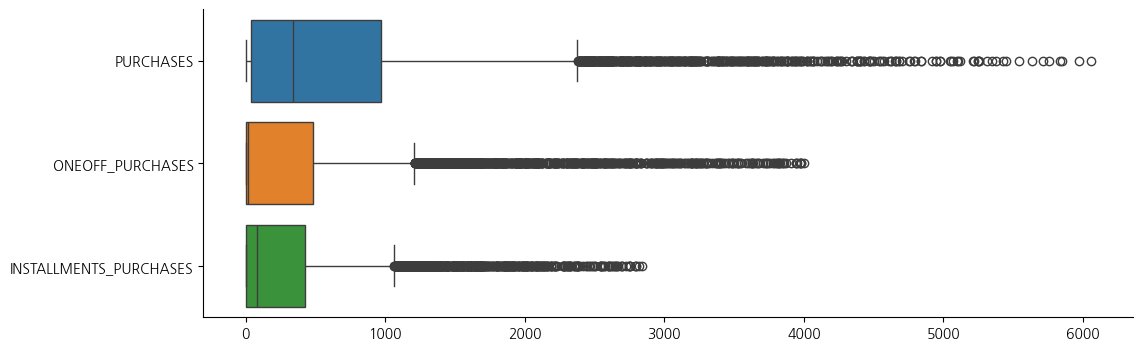
fig, ax = plt.subplots(figsize=(12, 4))
sns.boxplot(data=data[['PURCHASES','ONEOFF_PURCHASES','INSTALLMENTS_PURCHASES']], orient='h')
sns.despine()
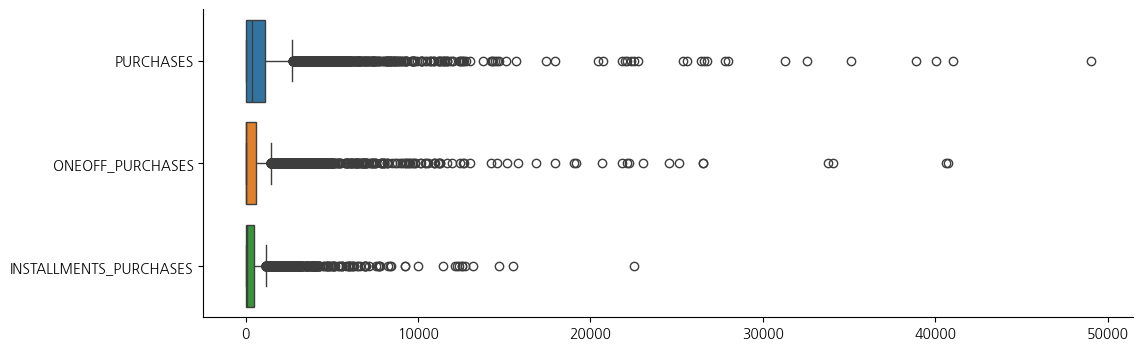
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 이상치가 전반적으로 많다. 조금 넓게 범위를 잡아 이상치를 처리해보자
# 이상치 처리 : IQR 0.10 ~ 0.90 기준
data1 = data.copy()
def get_outlier_mask(df, weight=1.5):
Q1 = df.quantile(0.10)
Q3 = df.quantile(0.90)
IQR = Q3 - Q1
IQR_weight = IQR * weight
range_min = Q1 - IQR_weight
range_max = Q3 + IQR_weight
outlier_per_column = (df < range_min) | (df > range_max)
is_outlier = outlier_per_column.any(axis=1)
return is_outlier
outlier_idx_cust_df = get_outlier_mask(data1, weight=1.5)
# 이상치를 제거한 데이터 프레임만 추가
data1 = data1[~outlier_idx_cust_df]
data1
| BALANCE | BALANCE_FREQUENCY | PURCHASES | ONEOFF_PURCHASES | INSTALLMENTS_PURCHASES | CASH_ADVANCE | PURCHASES_FREQUENCY | ONEOFF_PURCHASES_FREQUENCY | PURCHASES_INSTALLMENTS_FREQUENCY | CASH_ADVANCE_FREQUENCY | CASH_ADVANCE_TRX | PURCHASES_TRX | CREDIT_LIMIT | PAYMENTS | MINIMUM_PAYMENTS | PRC_FULL_PAYMENT | TENURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 40.900749 | 0.818182 | 95.40 | 0.00 | 95.40 | 0.000000 | 0.166667 | 0.000000 | 0.083333 | 0.000000 | 0 | 2 | 1000.0 | 201.802084 | 139.509787 | 0.000000 | 12 |
| 1 | 3202.467416 | 0.909091 | 0.00 | 0.00 | 0.00 | 6442.945483 | 0.000000 | 0.000000 | 0.000000 | 0.250000 | 4 | 0 | 7000.0 | 4103.032597 | 1072.340217 | 0.222222 | 12 |
| 2 | 2495.148862 | 1.000000 | 773.17 | 773.17 | 0.00 | 0.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0 | 12 | 7500.0 | 622.066742 | 627.284787 | 0.000000 | 12 |
| 3 | 1666.670542 | 0.636364 | 1499.00 | 1499.00 | 0.00 | 205.788017 | 0.083333 | 0.083333 | 0.000000 | 0.083333 | 1 | 1 | 7500.0 | 0.000000 | 0.000000 | 0.000000 | 12 |
| 4 | 817.714335 | 1.000000 | 16.00 | 16.00 | 0.00 | 0.000000 | 0.083333 | 0.083333 | 0.000000 | 0.000000 | 0 | 1 | 1200.0 | 678.334763 | 244.791237 | 0.000000 | 12 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 8908 | 21.357267 | 1.000000 | 212.87 | 0.00 | 212.87 | 0.000000 | 1.000000 | 0.000000 | 0.857143 | 0.000000 | 0 | 7 | 1000.0 | 169.713838 | 103.387362 | 1.000000 | 7 |
| 8909 | 641.282519 | 1.000000 | 750.00 | 750.00 | 0.00 | 0.000000 | 0.142857 | 0.142857 | 0.000000 | 0.000000 | 0 | 1 | 1000.0 | 105.582942 | 302.743881 | 0.000000 | 7 |
| 8910 | 356.108694 | 1.000000 | 465.00 | 465.00 | 0.00 | 0.000000 | 0.142857 | 0.142857 | 0.000000 | 0.000000 | 0 | 1 | 1000.0 | 118.775188 | 109.227176 | 0.000000 | 7 |
| 8911 | 30.709172 | 0.285714 | 693.42 | 0.00 | 693.42 | 0.000000 | 0.714286 | 0.000000 | 0.571429 | 0.000000 | 0 | 7 | 1000.0 | 1154.520085 | 15.853873 | 0.000000 | 7 |
| 8912 | 376.547421 | 0.857143 | 520.00 | 280.00 | 240.00 | 1178.402416 | 0.857143 | 0.142857 | 0.714286 | 0.714286 | 9 | 7 | 1000.0 | 929.415656 | 103.927887 | 0.200000 | 7 |
7860 rows × 17 columns
1
# 이상치 처리후 약 88% 데이터가 남아있음
1
2
3
4
5
6
7
8
9
10
11
# 이상치 제거 후 시각화
plt.figure(figsize=(20,16))
for index, col in enumerate(data1):
plt.subplot(4, 5, index + 1)
sns.boxplot(data=data1, y=col)
plt.title(f"{col} 데이터 분포")
plt.xlabel('')
plt.ylabel('')
plt.tight_layout()
plt.show()
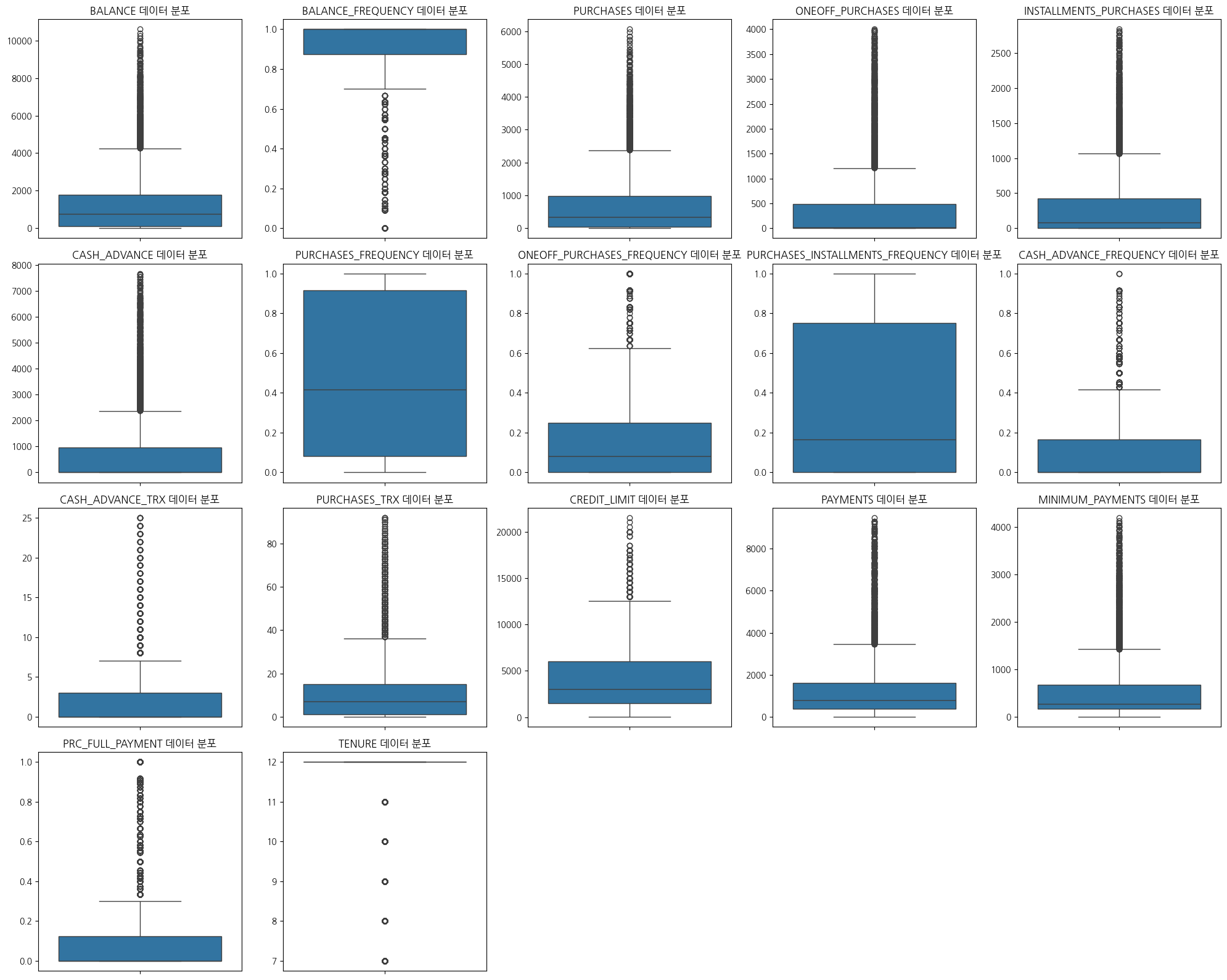
1
2
3
fig, ax = plt.subplots(figsize=(12, 4))
sns.boxplot(data=data1[['PURCHASES','ONEOFF_PURCHASES','INSTALLMENTS_PURCHASES']], orient='h')
sns.despine()
1
2
print(data.shape)
print(data1.shape)
1
2
(8949, 17)
(7860, 17)
데이터 스케일링(표준화)
1
2
3
4
from sklearn.preprocessing import StandardScaler
X = pd.DataFrame(StandardScaler().fit_transform(data1))
X.columns = data1.columns
X
| BALANCE | BALANCE_FREQUENCY | PURCHASES | ONEOFF_PURCHASES | INSTALLMENTS_PURCHASES | CASH_ADVANCE | PURCHASES_FREQUENCY | ONEOFF_PURCHASES_FREQUENCY | PURCHASES_INSTALLMENTS_FREQUENCY | CASH_ADVANCE_FREQUENCY | CASH_ADVANCE_TRX | PURCHASES_TRX | CREDIT_LIMIT | PAYMENTS | MINIMUM_PAYMENTS | PRC_FULL_PAYMENT | TENURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.759230 | -0.215174 | -0.647074 | -0.563016 | -0.438529 | -0.554399 | -0.781710 | -0.655372 | -0.686239 | -0.681795 | -0.583719 | -0.642731 | -0.963612 | -0.757110 | -0.619439 | -0.519522 | 0.342786 |
| 1 | 1.133722 | 0.157732 | -0.749856 | -0.563016 | -0.636488 | 4.353856 | -1.201890 | -0.655372 | -0.899298 | 0.741350 | 0.340635 | -0.777428 | 0.887054 | 2.054270 | 0.839021 | 0.253579 | 0.342786 |
| 2 | 0.710223 | 0.530637 | 0.083143 | 0.554549 | -0.636488 | -0.554399 | 1.319186 | 2.889453 | -0.899298 | -0.681795 | -0.583719 | 0.030752 | 1.041276 | -0.454251 | 0.143187 | -0.519522 | 0.342786 |
| 3 | 0.214181 | -0.960985 | 0.865139 | 1.603686 | -0.636488 | -0.397629 | -0.991802 | -0.359971 | -0.899298 | -0.207415 | -0.352631 | -0.710080 | 1.041276 | -0.902537 | -0.837560 | -0.519522 | 0.342786 |
| 4 | -0.294122 | 0.530637 | -0.732618 | -0.539889 | -0.636488 | -0.554399 | -0.991802 | -0.359971 | -0.899298 | -0.681795 | -0.583719 | -0.710080 | -0.901923 | -0.413702 | -0.454834 | -0.519522 | 0.342786 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7855 | -0.770931 | 0.530637 | -0.520514 | -0.563016 | -0.194773 | -0.554399 | 1.319186 | -0.655372 | 1.292180 | -0.681795 | -0.583719 | -0.305989 | -0.963612 | -0.780234 | -0.675916 | 2.959437 | -4.300951 |
| 7856 | -0.399758 | 0.530637 | 0.058180 | 0.521058 | -0.636488 | -0.554399 | -0.841737 | -0.148969 | -0.899298 | -0.681795 | -0.583719 | -0.710080 | -0.963612 | -0.826449 | -0.364226 | -0.519522 | -4.300951 |
| 7857 | -0.570503 | 0.530637 | -0.248873 | 0.109110 | -0.636488 | -0.554399 | -0.841737 | -0.148969 | -0.899298 | -0.681795 | -0.583719 | -0.710080 | -0.963612 | -0.816943 | -0.666785 | -0.519522 | -4.300951 |
| 7858 | -0.765332 | -2.399339 | -0.002778 | -0.563016 | 0.802390 | -0.554399 | 0.598879 | -0.655372 | 0.561688 | -0.681795 | -0.583719 | -0.305989 | -0.963612 | -0.070544 | -0.812773 | -0.519522 | -4.300951 |
| 7859 | -0.558265 | -0.055357 | -0.189617 | -0.158295 | -0.138477 | 0.343312 | 0.959032 | -0.148969 | 0.926934 | 3.384336 | 1.496078 | -0.305989 | -0.963612 | -0.232763 | -0.675071 | 0.176270 | -4.300951 |
7860 rows × 17 columns
데이터 분석
1
data1.describe()
| BALANCE | BALANCE_FREQUENCY | PURCHASES | ONEOFF_PURCHASES | INSTALLMENTS_PURCHASES | CASH_ADVANCE | PURCHASES_FREQUENCY | ONEOFF_PURCHASES_FREQUENCY | PURCHASES_INSTALLMENTS_FREQUENCY | CASH_ADVANCE_FREQUENCY | CASH_ADVANCE_TRX | PURCHASES_TRX | CREDIT_LIMIT | PAYMENTS | MINIMUM_PAYMENTS | PRC_FULL_PAYMENT | TENURE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 | 7860.000000 |
| mean | 1308.949829 | 0.870638 | 695.998356 | 389.514023 | 306.734674 | 727.745525 | 0.476737 | 0.184881 | 0.351739 | 0.119769 | 2.525954 | 11.543384 | 4124.103510 | 1252.410911 | 535.702676 | 0.149333 | 11.630916 |
| std | 1670.284112 | 0.243801 | 928.235177 | 691.878859 | 481.947855 | 1312.758971 | 0.396681 | 0.282119 | 0.391150 | 0.175678 | 4.327621 | 14.849117 | 3242.284051 | 1387.744782 | 639.640053 | 0.287461 | 1.076788 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 50.000000 | 0.000000 | 0.000000 | 0.000000 | 7.000000 |
| 25% | 101.167029 | 0.875000 | 37.877500 | 0.000000 | 0.000000 | 0.000000 | 0.083333 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 1500.000000 | 368.707269 | 161.920832 | 0.000000 | 12.000000 |
| 50% | 757.818931 | 1.000000 | 338.645000 | 20.000000 | 79.925000 | 0.000000 | 0.416667 | 0.083333 | 0.166667 | 0.000000 | 0.000000 | 7.000000 | 3000.000000 | 771.822248 | 269.924755 | 0.000000 | 12.000000 |
| 75% | 1765.044917 | 1.000000 | 972.447500 | 483.605000 | 426.602500 | 950.978173 | 0.916667 | 0.250000 | 0.750000 | 0.166667 | 3.000000 | 15.000000 | 6000.000000 | 1605.538063 | 666.702914 | 0.125000 | 12.000000 |
| max | 10598.467770 | 1.000000 | 6058.030000 | 4000.000000 | 2840.060000 | 7663.906258 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 25.000000 | 92.000000 | 21500.000000 | 9481.484058 | 4192.565071 | 1.000000 | 12.000000 |
EDA
1
2
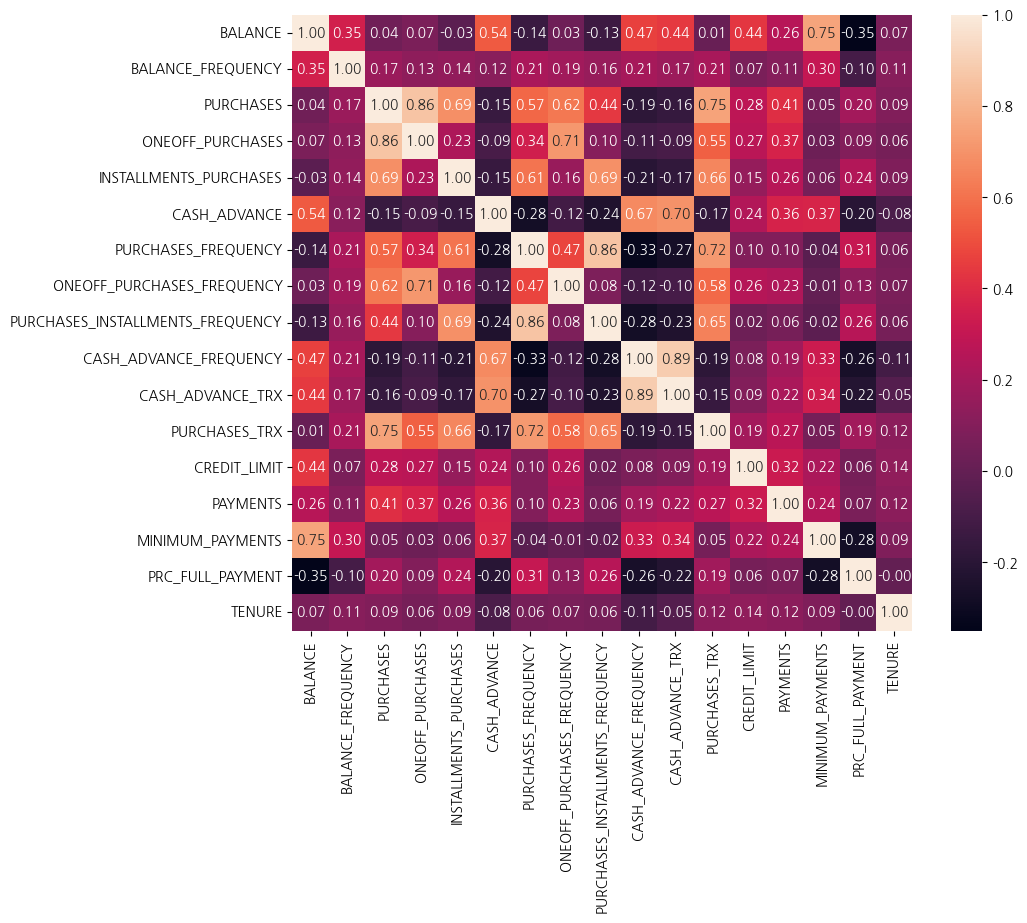
plt.figure(figsize=(10,8))
sns.heatmap(data1.corr(), annot=True, fmt='.2f')
1
<Axes: >
1
2
corr_list = data1.corr()['PURCHASES'].abs().sort_values(ascending = False)
corr_list
| PURCHASES | |
|---|---|
| PURCHASES | 1.000000 |
| ONEOFF_PURCHASES | 0.862674 |
| PURCHASES_TRX | 0.750810 |
| INSTALLMENTS_PURCHASES | 0.687412 |
| ONEOFF_PURCHASES_FREQUENCY | 0.616113 |
| PURCHASES_FREQUENCY | 0.571824 |
| PURCHASES_INSTALLMENTS_FREQUENCY | 0.437147 |
| PAYMENTS | 0.407756 |
| CREDIT_LIMIT | 0.279801 |
| PRC_FULL_PAYMENT | 0.196942 |
| CASH_ADVANCE_FREQUENCY | 0.189060 |
| BALANCE_FREQUENCY | 0.171853 |
| CASH_ADVANCE_TRX | 0.157633 |
| CASH_ADVANCE | 0.148370 |
| TENURE | 0.089850 |
| MINIMUM_PAYMENTS | 0.048712 |
| BALANCE | 0.039330 |
- 총 구매액 관련 상관관계는 일회성 구매액, 구매 횟수, 할부 구매액, 구매빈도 등이 높은 상관관계가 관찰되었다
1
2
3
4
5
6
7
8
9
10
plt.figure(figsize=(20,16))
for index, col in enumerate(data1):
plt.subplot(4, 5, index + 1)
sns.histplot(data1[col], kde=True)
plt.title(f"{col} 데이터 분포")
plt.xlabel('')
plt.ylabel('')
plt.tight_layout()
plt.show()
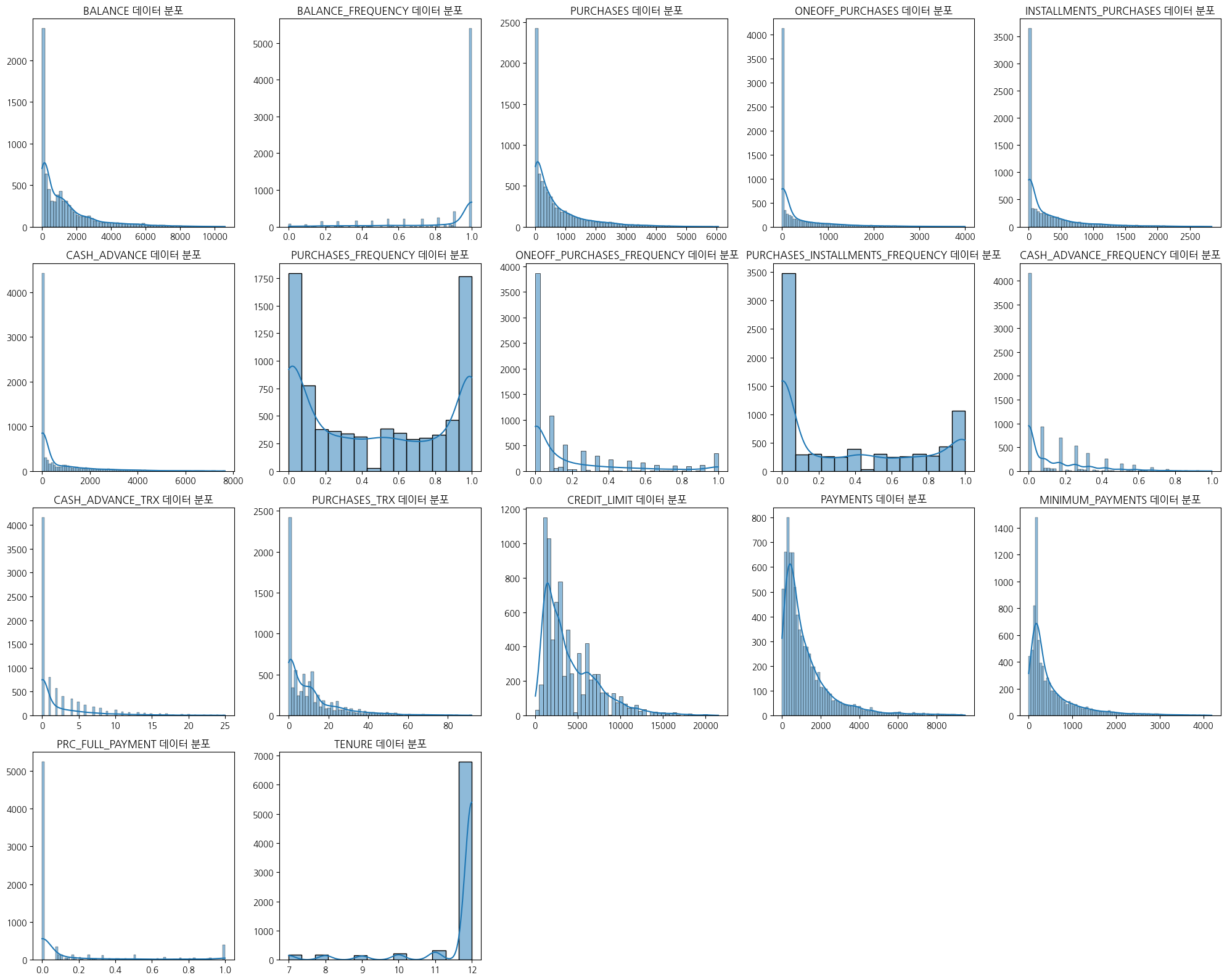
- 대부분 한쪽으로 치우쳐진 분포를 보이며 정규분포 형태는 관찰되지않음
주성분분석(PCA)
적절한 주성분 수 결정을 위해 분산 설명 비율 계산
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(X)
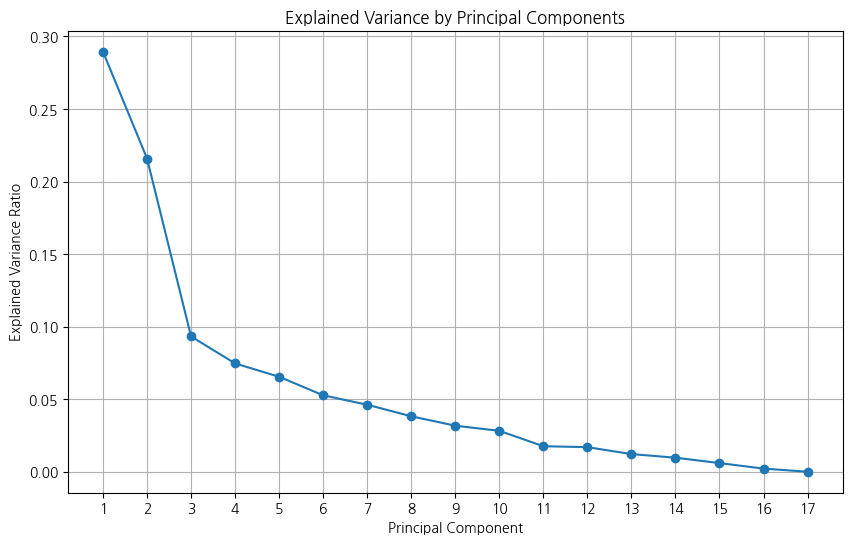
# 주성분의 설명력 (분산 설명 비율)
explained_variance = pca.explained_variance_ratio_
# 설명력 시각화
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(explained_variance) + 1), explained_variance, marker='o')
plt.title('Explained Variance by Principal Components')
plt.xlabel('Principal Component')
plt.ylabel('Explained Variance Ratio')
plt.xticks(range(1, len(explained_variance) + 1))
plt.grid()
plt.show()
# 누적 분산 비율 계산
cumulative_variance_ratio = np.cumsum(pca.explained_variance_ratio_)
print(cumulative_variance_ratio)
1
2
3
[0.28944758 0.50530762 0.59853074 0.67316781 0.73860167 0.79126589
0.83743209 0.87564215 0.90736008 0.93555131 0.95312777 0.97006002
0.982218 0.9918921 0.99784582 0.99999769 1. ]
1
2
3
4
5
# 주성분의 설명력이 70% 이상은 아니지만 완만하게 바뀌는 지점인 주성분 3차원 기준으로 데이터 변환 진행
pca = PCA(n_components=3)
pca.fit(X)
loadings = pd.DataFrame(pca.components_.T, columns=['PC1','PC2','PC3'], index=X.columns)
loadings
| PC1 | PC2 | PC3 | |
|---|---|---|---|
| BALANCE | -0.090241 | 0.420046 | 0.082117 |
| BALANCE_FREQUENCY | 0.069763 | 0.228970 | 0.214685 |
| PURCHASES | 0.383308 | 0.167065 | -0.174996 |
| ONEOFF_PURCHASES | 0.285660 | 0.174523 | -0.462194 |
| INSTALLMENTS_PURCHASES | 0.328199 | 0.071088 | 0.326693 |
| CASH_ADVANCE | -0.188539 | 0.361044 | 0.050141 |
| PURCHASES_FREQUENCY | 0.378707 | 0.007412 | 0.262844 |
| ONEOFF_PURCHASES_FREQUENCY | 0.273971 | 0.140280 | -0.406676 |
| PURCHASES_INSTALLMENTS_FREQUENCY | 0.320546 | -0.021893 | 0.494744 |
| CASH_ADVANCE_FREQUENCY | -0.220366 | 0.343392 | 0.084174 |
| CASH_ADVANCE_TRX | -0.201693 | 0.349779 | 0.094663 |
| PURCHASES_TRX | 0.383084 | 0.128440 | 0.078035 |
| CREDIT_LIMIT | 0.089493 | 0.256659 | -0.178085 |
| PAYMENTS | 0.110607 | 0.295697 | -0.151794 |
| MINIMUM_PAYMENTS | -0.054220 | 0.354595 | 0.193431 |
| PRC_FULL_PAYMENT | 0.174370 | -0.137956 | -0.008513 |
| TENURE | 0.066260 | 0.048020 | -0.007403 |
1
2
3
4
5
6
7
8
9
10
11
# 각 주성분별 막대 그래프 생성
fig, axes = plt.subplots(1, 3, figsize=(15, 6))
axes = axes.flatten()
# 각 주성분별 막대 그래프 생성
for i in range(3):
loadings.iloc[:, i].sort_values(ascending=True).plot(kind='barh', ax=axes[i])
axes[i].set_title(f'주성분 {i+1}')
plt.tight_layout()
plt.show()
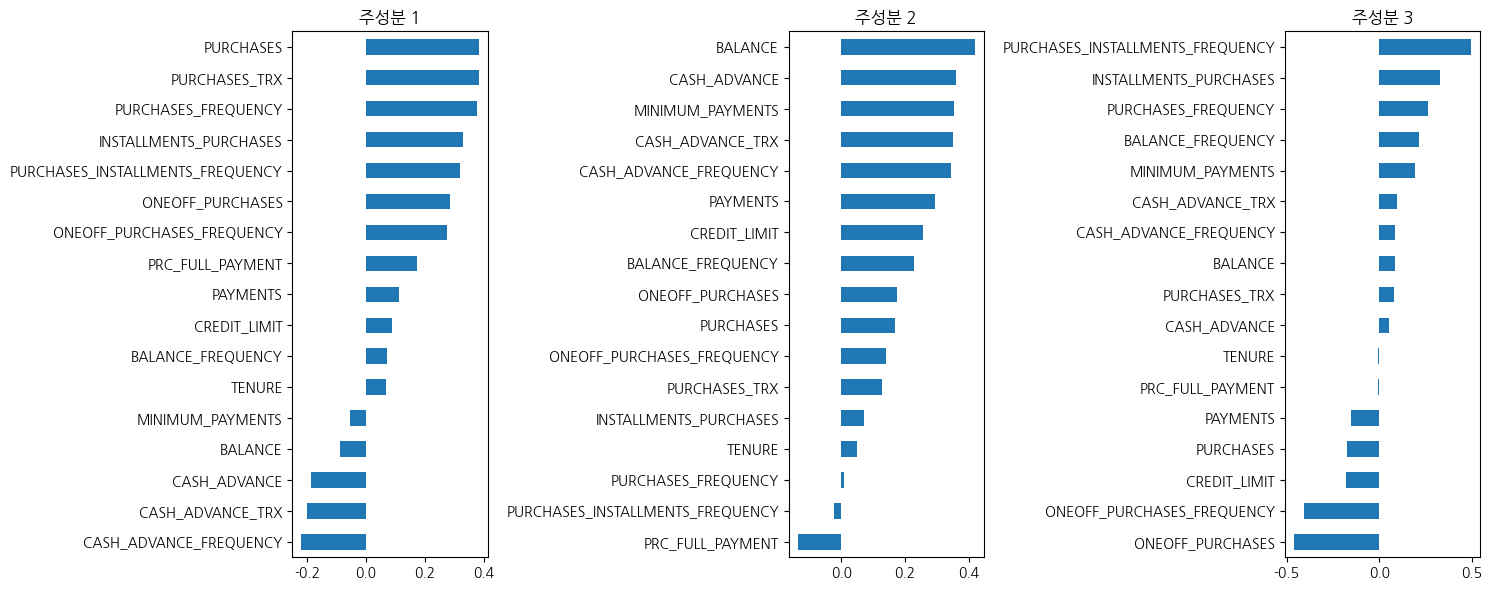
- 주성분1 : 구매 관련 변수에서 높은 수치, 현금서비스 관련 낮은 수치가 관찰됨
- 주성분2 : 잔액과 현금서비스, 지불액에서 높은 수치, 구매 관련 변수에서 낮은 수치가 관찰됨
- 주성분3 : 할부 구매 관련 변수에서 높은 수치, 일회성 구매는 낮은 수치가 관찰됨
PCA이용 차원축소후 K-means 클러스터링
1
2
3
4
pca.fit(X)
x_pca = pca.transform(X)
pca_df = pd.DataFrame(x_pca, columns=['PC1', 'PC2', 'PC3'])
pca_df.head()
| PC1 | PC2 | PC3 | |
|---|---|---|---|
| 0 | -1.272830 | -2.012145 | -0.178806 |
| 1 | -2.694168 | 3.122301 | -0.243752 |
| 2 | 1.308845 | 0.557380 | -1.804754 |
| 3 | -0.377355 | -0.426880 | -2.183236 |
| 4 | -1.412074 | -1.458696 | -0.358182 |
1
2
3
4
5
6
7
8
9
10
11
12
13
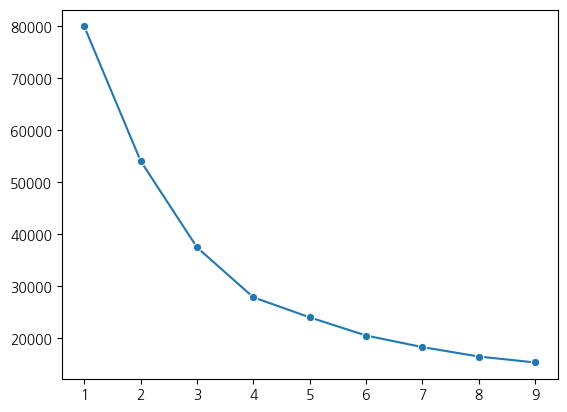
# 엘보우 기법 사용 적절한 k값 찾기
from sklearn.cluster import KMeans
ks = range(1,10)
inertias = []
for k in ks:
model = KMeans(n_clusters=k)
model.fit(pca_df)
inertias.append(model.inertia_)
#시각화
sns.lineplot(x=ks, y=inertias, marker='o')
1
<Axes: >
1
2
3
4
5
# 엘보우기법 시각화결과 군집개수 4개 기준으로 클러스터링 수행
optimal_k = 4
kmeans = KMeans(n_clusters=optimal_k, random_state=21)
pca_df['cluster'] = kmeans.fit_predict(pca_df)
pca_df
| PC1 | PC2 | PC3 | cluster | |
|---|---|---|---|---|
| 0 | -1.272830 | -2.012145 | -0.178806 | 2 |
| 1 | -2.694168 | 3.122301 | -0.243752 | 1 |
| 2 | 1.308845 | 0.557380 | -1.804754 | 3 |
| 3 | -0.377355 | -0.426880 | -2.183236 | 2 |
| 4 | -1.412074 | -1.458696 | -0.358182 | 2 |
| ... | ... | ... | ... | ... |
| 7855 | 0.767003 | -2.522112 | 1.592477 | 0 |
| 7856 | -1.045493 | -1.483827 | -0.916429 | 2 |
| 7857 | -1.248002 | -1.783215 | -0.746284 | 2 |
| 7858 | 0.060164 | -2.381332 | 0.543761 | 0 |
| 7859 | -1.056441 | 0.633322 | 1.301161 | 2 |
7860 rows × 4 columns
1
2
3
4
# 클러스터 개수 확인
cluster_counts = pca_df['cluster'].value_counts()
print("Cluster Counts:")
print(cluster_counts)
1
2
3
4
5
6
7
Cluster Counts:
cluster
2 3360
0 2048
1 1336
3 1116
Name: count, dtype: int64
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
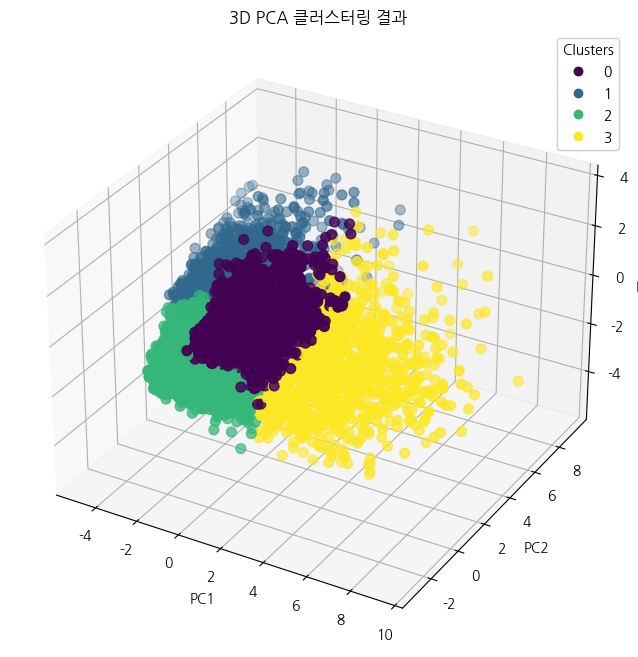
# 3D 시각화
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 클러스터에 따라 다른 색상으로 시각화
scatter = ax.scatter(pca_df['PC1'], pca_df['PC2'], pca_df['PC3'],
c=pca_df['cluster'], cmap='viridis', s=50)
# 축 레이블 설정
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
ax.set_title('3D PCA 클러스터링 결과')
# 범례 추가
legend1 = ax.legend(*scatter.legend_elements(), title="Clusters")
ax.add_artist(legend1)
plt.show()
1
2
data3 = X.copy()
data3['cluster'] = pca_df['cluster']
1
data3
| BALANCE | BALANCE_FREQUENCY | PURCHASES | ONEOFF_PURCHASES | INSTALLMENTS_PURCHASES | CASH_ADVANCE | PURCHASES_FREQUENCY | ONEOFF_PURCHASES_FREQUENCY | PURCHASES_INSTALLMENTS_FREQUENCY | CASH_ADVANCE_FREQUENCY | CASH_ADVANCE_TRX | PURCHASES_TRX | CREDIT_LIMIT | PAYMENTS | MINIMUM_PAYMENTS | PRC_FULL_PAYMENT | TENURE | cluster | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.759230 | -0.215174 | -0.647074 | -0.563016 | -0.438529 | -0.554399 | -0.781710 | -0.655372 | -0.686239 | -0.681795 | -0.583719 | -0.642731 | -0.963612 | -0.757110 | -0.619439 | -0.519522 | 0.342786 | 2 |
| 1 | 1.133722 | 0.157732 | -0.749856 | -0.563016 | -0.636488 | 4.353856 | -1.201890 | -0.655372 | -0.899298 | 0.741350 | 0.340635 | -0.777428 | 0.887054 | 2.054270 | 0.839021 | 0.253579 | 0.342786 | 1 |
| 2 | 0.710223 | 0.530637 | 0.083143 | 0.554549 | -0.636488 | -0.554399 | 1.319186 | 2.889453 | -0.899298 | -0.681795 | -0.583719 | 0.030752 | 1.041276 | -0.454251 | 0.143187 | -0.519522 | 0.342786 | 3 |
| 3 | 0.214181 | -0.960985 | 0.865139 | 1.603686 | -0.636488 | -0.397629 | -0.991802 | -0.359971 | -0.899298 | -0.207415 | -0.352631 | -0.710080 | 1.041276 | -0.902537 | -0.837560 | -0.519522 | 0.342786 | 2 |
| 4 | -0.294122 | 0.530637 | -0.732618 | -0.539889 | -0.636488 | -0.554399 | -0.991802 | -0.359971 | -0.899298 | -0.681795 | -0.583719 | -0.710080 | -0.901923 | -0.413702 | -0.454834 | -0.519522 | 0.342786 | 2 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7855 | -0.770931 | 0.530637 | -0.520514 | -0.563016 | -0.194773 | -0.554399 | 1.319186 | -0.655372 | 1.292180 | -0.681795 | -0.583719 | -0.305989 | -0.963612 | -0.780234 | -0.675916 | 2.959437 | -4.300951 | 0 |
| 7856 | -0.399758 | 0.530637 | 0.058180 | 0.521058 | -0.636488 | -0.554399 | -0.841737 | -0.148969 | -0.899298 | -0.681795 | -0.583719 | -0.710080 | -0.963612 | -0.826449 | -0.364226 | -0.519522 | -4.300951 | 2 |
| 7857 | -0.570503 | 0.530637 | -0.248873 | 0.109110 | -0.636488 | -0.554399 | -0.841737 | -0.148969 | -0.899298 | -0.681795 | -0.583719 | -0.710080 | -0.963612 | -0.816943 | -0.666785 | -0.519522 | -4.300951 | 2 |
| 7858 | -0.765332 | -2.399339 | -0.002778 | -0.563016 | 0.802390 | -0.554399 | 0.598879 | -0.655372 | 0.561688 | -0.681795 | -0.583719 | -0.305989 | -0.963612 | -0.070544 | -0.812773 | -0.519522 | -4.300951 | 0 |
| 7859 | -0.558265 | -0.055357 | -0.189617 | -0.158295 | -0.138477 | 0.343312 | 0.959032 | -0.148969 | 0.926934 | 3.384336 | 1.496078 | -0.305989 | -0.963612 | -0.232763 | -0.675071 | 0.176270 | -4.300951 | 2 |
7860 rows × 18 columns
1
2
3
4
# 클러스터별 고객 특성 파악하기
mask1 = data3.groupby('cluster').mean()
mask1['cluster_counts'] = data3['cluster'].value_counts()
mask1.T
| cluster | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| BALANCE | -0.439621 | 1.345252 | -0.311816 | 0.135114 |
| BALANCE_FREQUENCY | 0.161979 | 0.409125 | -0.393979 | 0.399143 |
| PURCHASES | 0.060833 | -0.425654 | -0.476633 | 1.832951 |
| ONEOFF_PURCHASES | -0.364703 | -0.291965 | -0.270482 | 1.833151 |
| INSTALLMENTS_PURCHASES | 0.641619 | -0.401137 | -0.529912 | 0.898198 |
| CASH_ADVANCE | -0.450776 | 1.544578 | -0.238864 | -0.302675 |
| PURCHASES_FREQUENCY | 0.982258 | -0.612000 | -0.702782 | 1.045982 |
| ONEOFF_PURCHASES_FREQUENCY | -0.350751 | -0.291416 | -0.253245 | 1.754995 |
| PURCHASES_INSTALLMENTS_FREQUENCY | 1.164645 | -0.535940 | -0.688415 | 0.576969 |
| CASH_ADVANCE_FREQUENCY | -0.508466 | 1.524861 | -0.181088 | -0.347151 |
| CASH_ADVANCE_TRX | -0.457004 | 1.552293 | -0.232616 | -0.319293 |
| PURCHASES_TRX | 0.360227 | -0.449306 | -0.558947 | 1.559669 |
| CREDIT_LIMIT | -0.286768 | 0.553079 | -0.293469 | 0.747710 |
| PAYMENTS | -0.277961 | 0.578240 | -0.341514 | 0.846080 |
| MINIMUM_PAYMENTS | -0.193486 | 1.073920 | -0.320739 | 0.035110 |
| PRC_FULL_PAYMENT | 0.402595 | -0.433647 | -0.201980 | 0.388433 |
| TENURE | -0.002320 | -0.029130 | -0.061053 | 0.222947 |
| cluster_counts | 2048.000000 | 1336.000000 | 3360.000000 | 1116.000000 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
for i in range(4): # 0, 1, 2, 3 클러스터 모두 포함
if i not in mask1.index:
mask1.loc[i] = [0] * (mask1.shape[1] - 1) + [0] # 평균값 0으로 설정
else:
mask1.loc[i, 'cluster_counts'] = mask1['cluster_counts'].get(i, 0) # 클러스터 개수 유지
mask1 = mask1.sort_index() # 인덱스 정렬
# 그래프 생성
fig, axes = plt.subplots(3, 2, figsize=(12, 18)) # 3행 2열의 서브플롯 설정
axes = axes.flatten()
# 각 클러스터별 평균값 시각화
for i in range(len(mask1) - 1): # 클러스터 평균값에 대해서만
mask1.iloc[i].drop('cluster_counts').sort_values(ascending=True).plot(kind='barh', ax=axes[i])
axes[i].set_title(f'클러스터 {i}')
# 클러스터 개수 그래프
mask1['cluster_counts'][:4].plot(kind='barh', ax=axes[4], color='orange')
axes[4].set_xlabel('고객 수')
axes[4].set_ylabel('클러스터')
# 남는 서브플롯 비우기
axes[5].axis('off') # 여섯 번째 서브플롯은 비워둡니다.
plt.tight_layout()
plt.show()
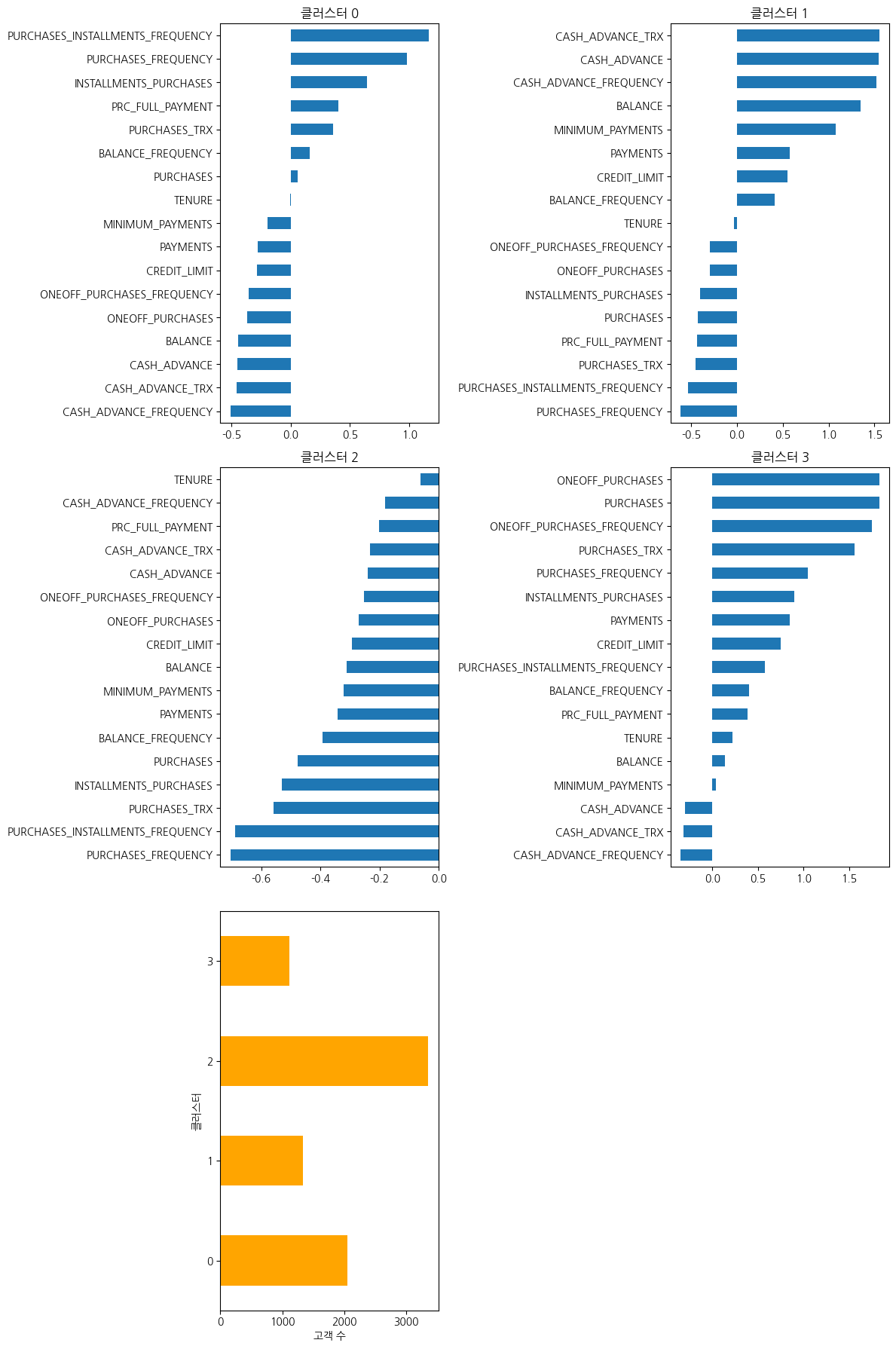
- 클러스터0(할부 구매가 활발한 고객)
- 구매 빈도와 할부 구매 비율이 높고, 현금서비스와 일회성 구매는 낮게 관찰됨
- 일회성 구매보다는 소액으로 나누어 자주 구매하는 성향을 보이고 있음
- 마케팅 전략
- 장기 할부 혜택이나 포인트 적립 프로그램을 제안하여 다양한 상품을 구매할 수 있도록 유도.특정 고가의 상품을 할부로 구매하는 방향도 검토 필요
- 해당유형은 빈번한 할부 구매로 회사의 제품에 만족하고있다. 지인을 추천할 경우 다양한 혜택을 제공하여 더많은 충성고객 확보(비슷한 성향의 사람들이 유입되어 충성고객이 늘어날 수 있음
- 클러스터1(현금 서비스 이용고객)
- 현금 서비스 사용 빈도가 높고 잔액과 최소지불액 또한 높게 관찰됨
- 구매 관련 변수들이 평균이하로, 구매보다는 현금 서비스를 많이 이용하는 고객
- 마케팅 전략
- 대출 이자율을 개선해주는 프로모션이나 현금서비스 대체 상품 프로그램 제공
- 고객의 재무관리 상담 서비스를 도입하여 원활한 현금흐름 유도
- 클러스터2(소극적인 고객)
- 모든 지표들이 평균이하로, 특히 구매관련빈도가 매우 낮게 관찰됨
- 카드 사용 활동이 거의 없고, 소비에 대해 신중해 구매를 자주하지 않고 필요할 때만 거래를 하는 경향이 관찰됨
- 마케팅 전략
- 카드 사용 유도를 위해 사용 빈도에 따라 할인 혜택을 제공하거나 초기 혜택 제공
- 관심 상품들을 분석하여 특별 할인이나 1+1 행사 등 관심을 지속적으로 유도하여 구매빈도를 높임
- 고객의 구매 주기를 파악하여 적절한 주기를 설정하여 관심 상품에 대한 안내를 개인화하여 고객의 관심유도
- 현금서비스 이용을 유도하기 위해 낮은 이자율이나 장기적인 대출 서비스 제공 검토 혹은 재무관리 상담 서비스 제공
- 클러스터3(VIP 고객)
- 총 구매액과 일회성 구매액, 구매 빈도 등 가장 높게 관찰됨
- 현금서비스 이용은 평균이하로 관찰되며, 고액상품을 일시불로 구매하는 유형
- 마케팅 전략
- VIP서비스나 고액상품 구매시 제공되는 혜택을 강조하고, VIP대상 이벤트나 한정된 고가상품 구매 우선권 제공 등 구매를 유도할 수 있는 이벤트 제공
This post is licensed under CC BY 4.0 by the author.