데이터 위클리 페이퍼 5 - 사분위수, 기술통계와 추론통계
- 데이터 위클리 페이퍼 12 - 머신러닝 편향과 분산, K-폴드
- 데이터 위클리 페이퍼 11 - 지도학습과 비지도학습, 손실 함수
- 데이터 위클리 페이퍼 10 - A/B테스트, Event Taxonomy
- 데이터 위클리 페이퍼 9 - AARRR 사례 분석
- 데이터 위클리 페이퍼 8 - AARRR, 코호트와 세그먼트, RFM
- 데이터 위클리 페이퍼 7 - 장바구니 분석(연관분석)
- 데이터 위클리 페이퍼 6 - 클러스터링, 고유값과 고유벡터, 히스토그램
- 데이터 위클리 페이퍼 4 - 데이터 전처리와 t-test
- 데이터 위클리 페이퍼 3 - 제1종 오류와 제2종 오류, p-value
- 데이터 위클리 페이퍼 2 - 유닉스 절대경로와 상대경로, 깃 브랜치
- 데이터 위클리 페이퍼 1 - 클래스와 인스턴스, 정적 메소드
사분위수에 대해 설명해주세요
- 사분위수(Quartile)?
- 데이터 4등분한 것
- 데이터를 상위 25%, 상위 50%, 하위 25%(상위75%)의 지점으로 나누는 기준점
- 중간에 위치하는 상위 50%는
중간값, 상위 25%는3분위수, 하위 25%는1분위수로 표현
- IQR(Interquartile Range)
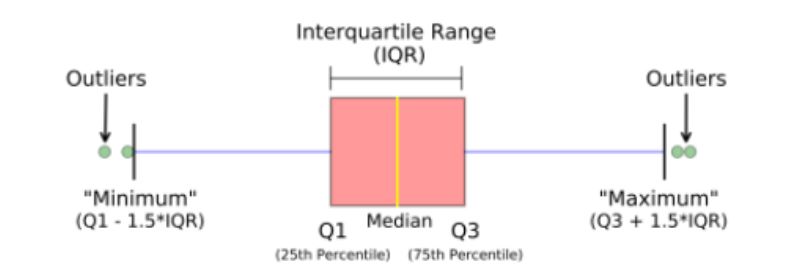
사분위수 사이의 범위를 뜻하며 3사분위수와 1사분위수 사이의 범위를 표현- IQR을 이용하여 데이터 이상치 제거 활용
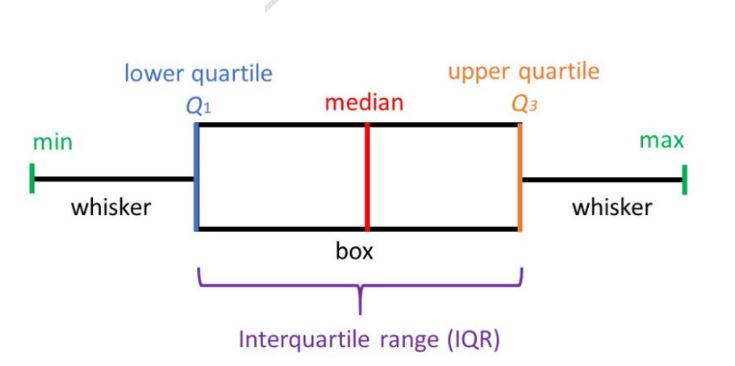
- IQR = Q3 - Q1
- 너무 작은 이상치 : Q1 - 1.5 * IQR
- 너무 큰 이상치 : Q3 + 1.5 * IQR
기술통계와 추론통계는 무엇이고, 어떤 차이가 있나요?
- 기술통계(Descriptive Statistics) : 데이터 집합을 수치적으로 요약하거나 시각화하여 특성 파악
- 중심 경향성 측정 : 평균, 중간값, 최빈값 등을 통해 데이터의 중심을 파악
- 산포도 측정 : 분산, 표준편차, 범위 등을 통해 데이터픠 퍼짐 정도를 분석
- 시각화 : 히스토그램, 박스 플롯, 산점도 등을 사용하여 데이터의 분포와 패턴을 시각화
- 데이터를 이해하고 패턴을 파악해 수치적으로 중요한 데이터를 강조하는데 사용
- 예시 : 회사의 직원 급여 데이터를 분석할 때, 급여 분포와 평균 급여를 시각화하여 급여 수준 파악
- 추론통계(Inferential Statistics) : 표본 데이터를 사용해 모집단의 특성을 추정
- 표본 추출 : 모집단에서 무작위로 표본을 선택하여 분석
- 가설 검정 : 통계적 검증을 수행해 가설 검증
- 신뢰 구간 : 모집단의 모수 추정 시, 그 값이 포함될 것으로 예상되는 범위를 제공
- 예시 : 제품 소비자 만족도 조사 → 전체 고객 대신 샘플을 정해 평균 만족도 추정 → 전체 고객 만족도 추론
- 기술통계와 추론통계의 차이
- 사용목적
- 기술통계 : 데이터를 요약하고 정리하는데 중점
- 추론통계 : 표본 데이터를 사용해 모집단 추정(확률적 접근)
- 데이터 선택
- 기술통계 : 전체 데이터 집합을 분석
- 추론통계 : 표본 데이터 기반 분석
- 사용목적
This post is licensed under CC BY 4.0 by the author.